 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control
Paper and Code
Aug 20, 2021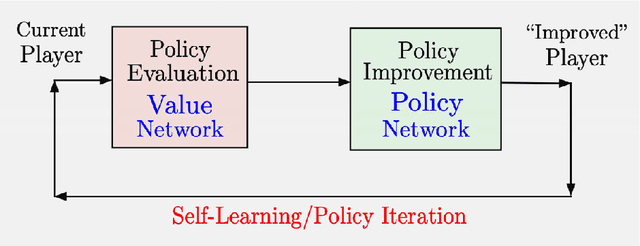
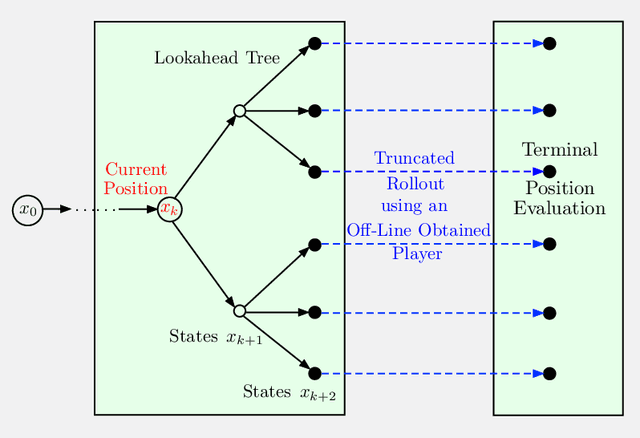
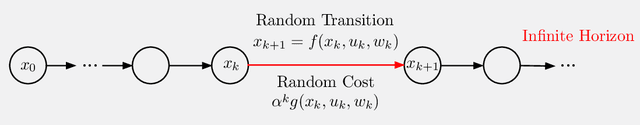
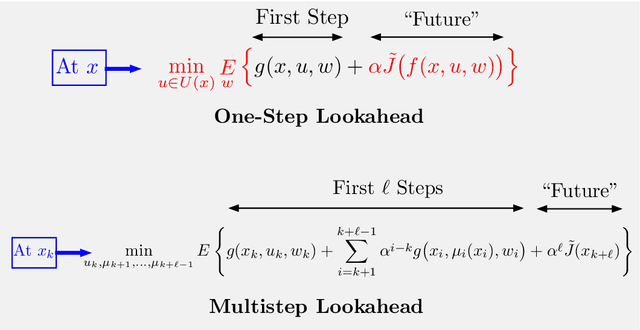
In this paper we aim to provide analysis and insights (often based on visualization), which explain the beneficial effects of on-line decision making on top of off-line training. In particular, through a unifying abstract mathematical framework, we show that the principal AlphaZero/TD-Gammon ideas of approximation in value space and rollout apply very broadly to deterministic and stochastic optimal control problems, involving both discrete and continuous search spaces. Moreover, these ideas can be effectively integrated with other important methodologies such as model predictive control, adaptive control, decentralized control, discrete and Bayesian optimization, neural network-based value and policy approximations, and heuristic algorithms for discrete optimization.