 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with convolution and pooling operations in kernel methods
Paper and Code
Nov 16, 2021


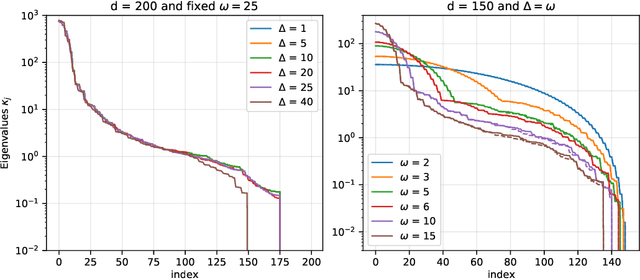
Recent empirical work has shown that hierarchical convolutional kernels inspired by convolutional neural networks (CNNs) significantly improve the performance of kernel methods in image classification tasks. A widely accepted explanation for the success of these architectures is that they encode hypothesis classes that are suitable for natural images. However, understanding the precise interplay between approximation and generalization in convolutional architectures remains a challenge. In this paper, we consider the stylized setting of covariates (image pixels) uniformly distributed on the hypercube, and fully characterize the RKHS of kernels composed of single layers of convolution, pooling, and downsampling operations. We then study the gain in sample efficiency of kernel methods using these kernels over standard inner-product kernels. In particular, we show that 1) the convolution layer breaks the curse of dimensionality by restricting the RKHS to `local' functions; 2) local pooling biases learning towards low-frequency functions, which are stable by small translations; 3) downsampling may modify the high-frequency eigenspaces but leaves the low-frequency part approximately unchanged. Notably, our results quantify how choosing an architecture adapted to the target function leads to a large improvement in the sample complexity.