 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Video Representations from Textual Web Supervision
Paper and Code
Jul 29, 2020
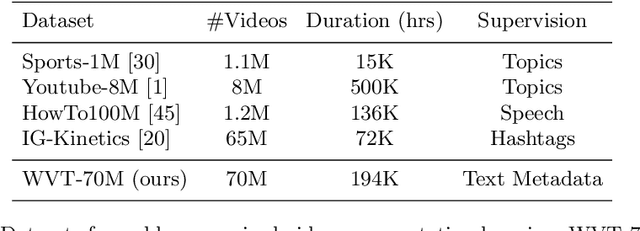
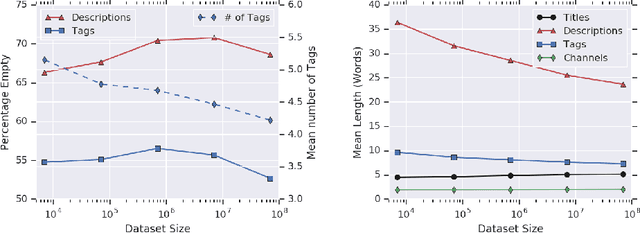

Videos found on the Internet are paired with pieces of text, such as titles and descriptions. This text typically describes the most important content in the video, such as the objects in the scene and the actions being performed. Based on this observation, we propose to use such text as a method for learning video representations. To accomplish this, we propose a data collection process and use it to collect 70M video clips shared publicly on the Internet, and we then train a model to pair each video with its associated text. We fine-tune the model on several down-stream action recognition tasks, including Kinetics, HMDB-51, and UCF-101. We find that this approach is an effective method of pretraining video representations. Specifically, it leads to improvements over from-scratch training on all benchmarks, outperforms many methods for self-supervised and webly-supervised video representation learning, and achieves an improvement of 2.2% accuracy on HMDB-51.