 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to segment images with classification labels
Paper and Code
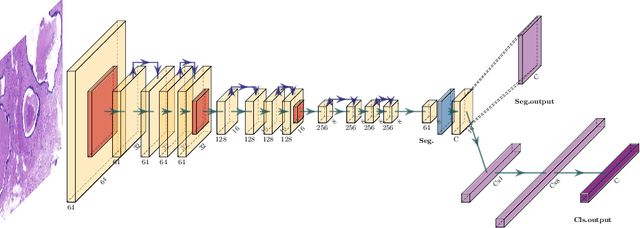
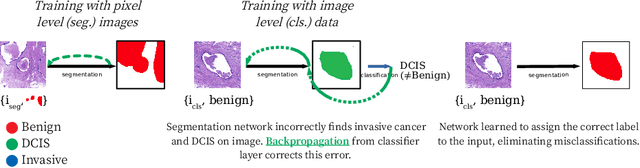
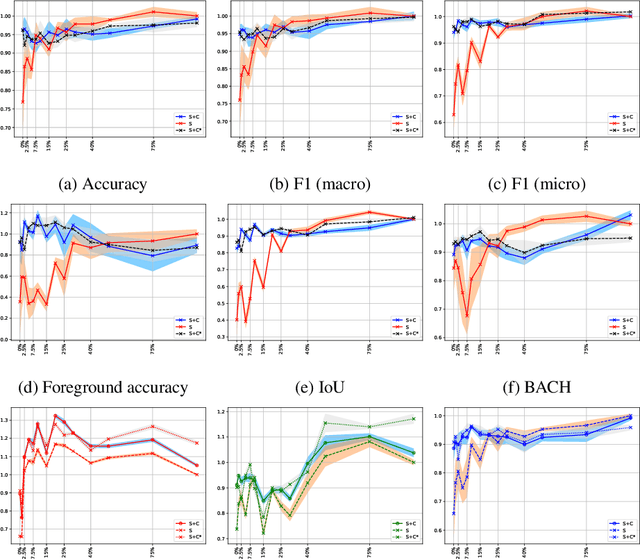

Two of the most common tasks in medical imaging are classification and segmentation. Either task requires labeled data annotated by experts, which is scarce and expensive to collect. Annotating data for segmentation is generally considered to be more laborious as the annotator has to draw around the boundaries of regions of interest, as opposed to assigning image patches a class label. Furthermore, in tasks such as breast cancer histopathology, any realistic clinical application often includes working with whole slide images, whereas most publicly available training data are in the form of image patches, which are given a class label. We propose an architecture that can alleviate the requirements for segmentation-level ground truth by making use of image-level labels to reduce the amount of time spent on data curation. In addition, this architecture can help unlock the potential of previously acquired image-level datasets on segmentation tasks by annotating a small number of regions of interest. In our experiments, we show using only one segmentation-level annotation per class, we can achieve performance comparable to a fully annotated dataset.