 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compose Diversified Prompts for Image Emotion Classification
Paper and Code
Jan 26, 2022
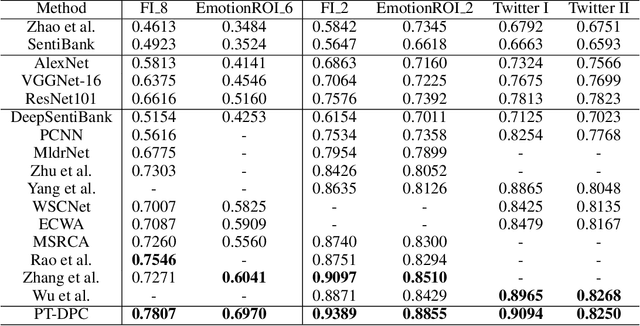
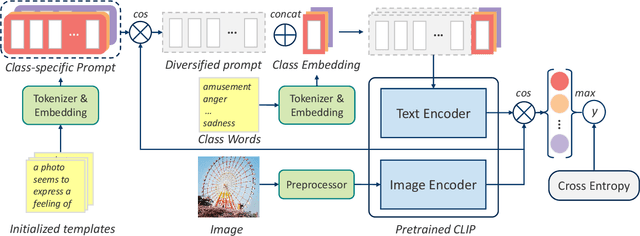

Contrastive Language-Image Pre-training (CLIP) represents the latest incarnation of pre-trained vision-language models. Although CLIP has recently shown its superior power on a wide range of downstream vision-language tasks like Visual Question Answering, it is still underexplored for Image Emotion Classification (IEC). Adapting CLIP to the IEC task has three significant challenges, tremendous training objective gap between pretraining and IEC, shared suboptimal and invariant prompts for all instances. In this paper, we propose a general framework that shows how CLIP can be effectively applied to IEC. We first introduce a prompt tuning method that mimics the pretraining objective of CLIP and thus can leverage the rich image and text semantics entailed in CLIP. Then we automatically compose instance-specific prompts by conditioning them on the categories and image contents of instances, diversifying prompts and avoiding suboptimal problems. Evaluations on six widely-used affective datasets demonstrate that our proposed method outperforms the state-of-the-art methods to a large margin (i.e., up to 9.29% accuracy gain on EmotionROI dataset) on IEC tasks, with only a few parameters trained. Our codes will be publicly available for research purposes.