 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Communicate in Multi-Agent Reinforcement Learning : A Review
Paper and Code
Nov 13, 2019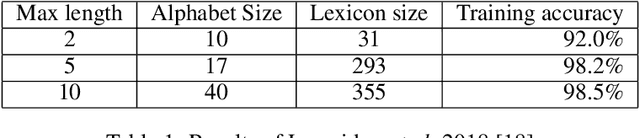

We consider the issue of multiple agents learning to communicate through reinforcement learning within partially observable environments, with a focus on information asymmetry in the second part of our work. We provide a review of the recent algorithms developed to improve the agents' policy by allowing the sharing of information between agents and the learning of communication strategies, with a focus on Deep Recurrent Q-Network-based models. We also describe recent efforts to interpret the languages generated by these agents and study their properties in an attempt to generate human-language-like sentences. We discuss the metrics used to evaluate the generated communication strategies and propose a novel entropy-based evaluation metric. Finally, we address the issue of the cost of communication and introduce the idea of an experimental setup to expose this cost in cooperative-competitive game.