 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Accelerate by the Methods of Step-size Planning
Paper and Code
Apr 15, 2022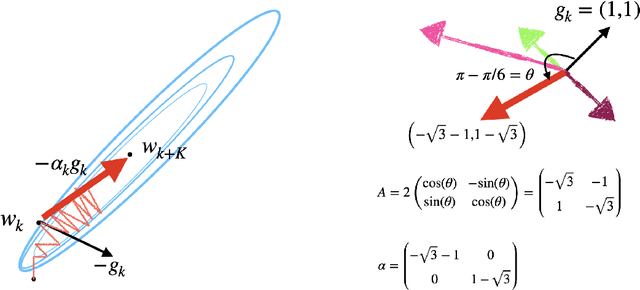
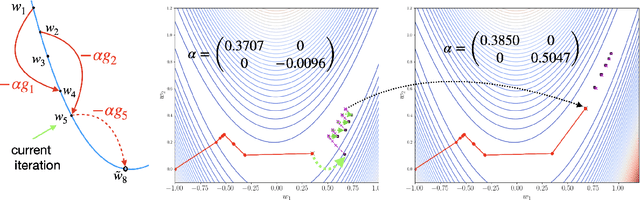
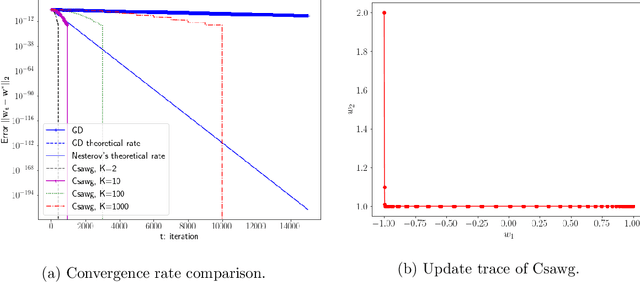
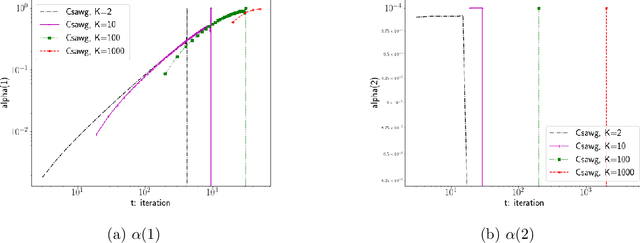
Gradient descent is slow to converge for ill-conditioned problems and non-convex problems. An important technique for acceleration is step-size adaptation. The first part of this paper contains a detailed review of step-size adaptation methods, including Polyak step-size, L4, LossGrad, Adam, IDBD, and Hypergradient descent, and the relation of step-size adaptation to meta-gradient methods. In the second part of this paper, we propose a new class of methods of accelerating gradient descent that have some distinctiveness from existing techniques. The new methods, which we call {\em step-size planning}, use the {\em update experience} to learn an improved way of updating the parameters. The methods organize the experience into $K$ steps away from each other to facilitate planning. From the past experience, our planning algorithm, Csawg, learns a step-size model which is a form of multi-step machine that predicts future updates. We extends Csawg to applying step-size planning multiple steps, which leads to further speedup. We discuss and highlight the projection power of the diagonal-matrix step-size for future large scale applications. We show for a convex problem, our methods can surpass the convergence rate of Nesterov's accelerated gradient, $1 - \sqrt{\mu/L}$, where $\mu, L$ are the strongly convex factor of the loss function $F$ and the Lipschitz constant of $F'$, which is the theoretical limit for the convergence rate of first-order methods. On the well-known non-convex Rosenbrock function, our planning methods achieve zero error below 500 gradient evaluations, while gradient descent takes about 10000 gradient evaluations to reach a $10^{-3}$ accuracy. We discuss the connection of step-size planing to planning in reinforcement learning, in particular, Dyna architectures.