 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Time/Memory-Efficient Deep Architectures with Budgeted Super Networks
Paper and Code
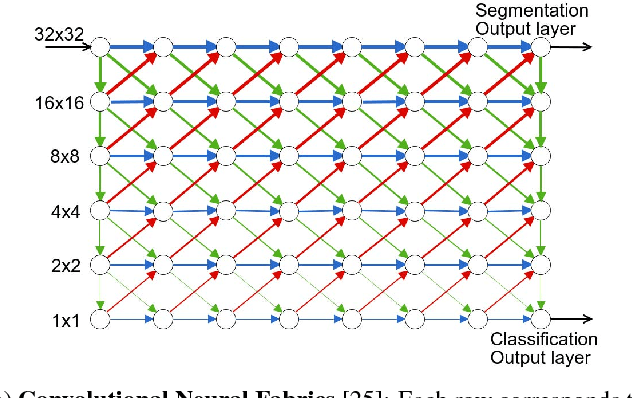
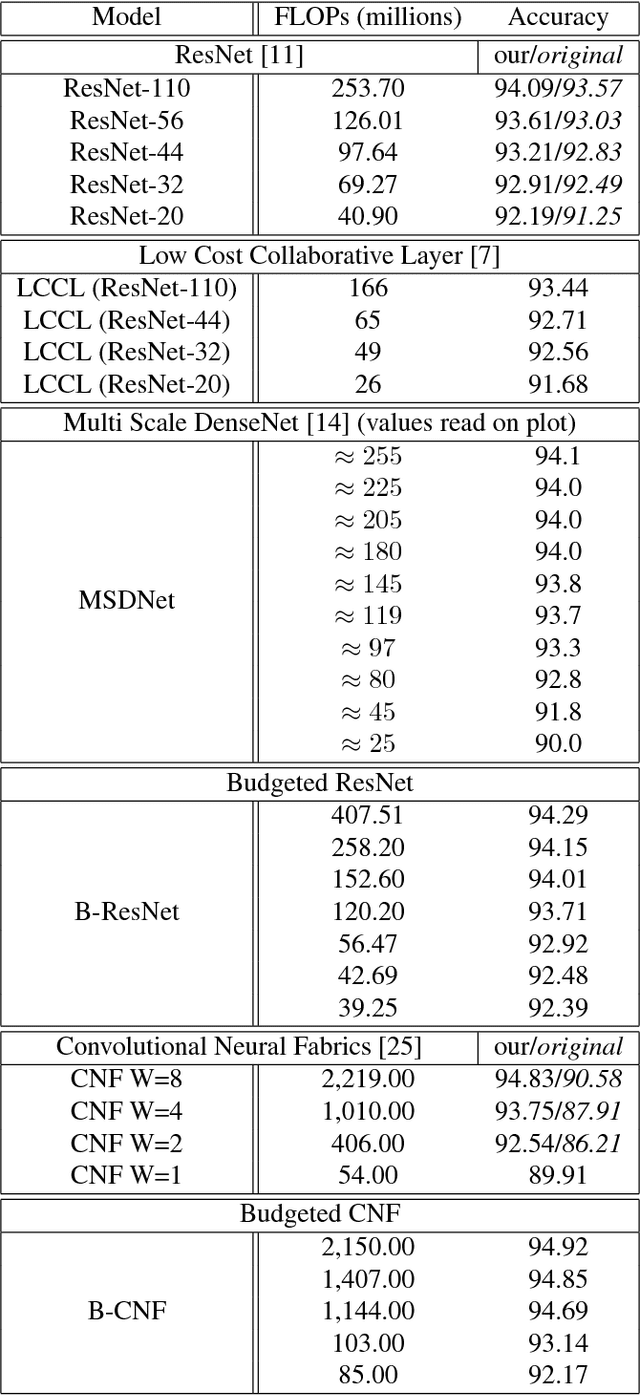
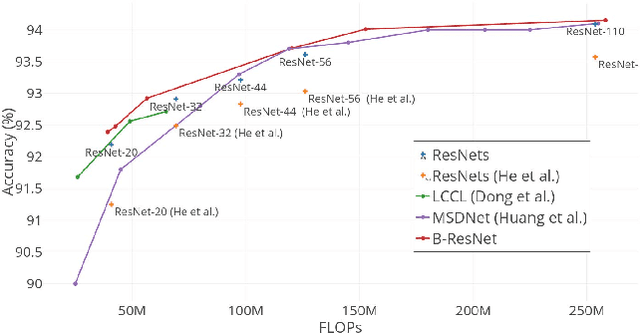
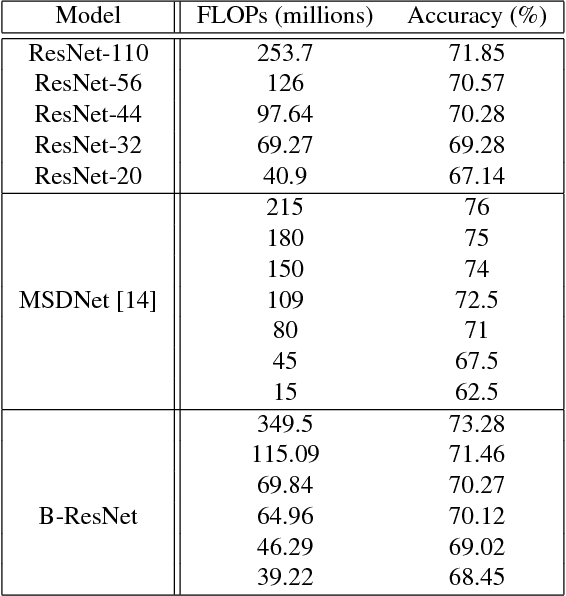
We propose to focus on the problem of discovering neural network architectures efficient in terms of both prediction quality and cost. For instance, our approach is able to solve the following tasks: learn a neural network able to predict well in less than 100 milliseconds or learn an efficient model that fits in a 50 Mb memory. Our contribution is a novel family of models called Budgeted Super Networks (BSN). They are learned using gradient descent techniques applied on a budgeted learning objective function which integrates a maximum authorized cost, while making no assumption on the nature of this cost. We present a set of experiments on computer vision problems and analyze the ability of our technique to deal with three different costs: the computation cost, the memory consumption cost and a distributed computation cost. We particularly show that our model can discover neural network architectures that have a better accuracy than the ResNet and Convolutional Neural Fabrics architectures on CIFAR-10 and CIFAR-100, at a lower cost.