 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Polymatrix Games in Polynomial Time and Sample Complexity
Paper and Code
Nov 20, 2017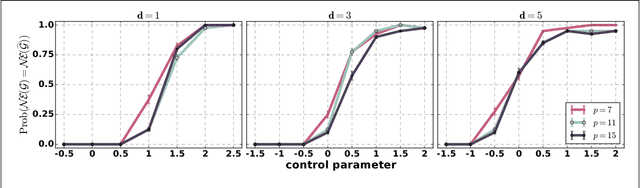
We consider the problem of learning sparse polymatrix games from observations of strategic interactions. We show that a polynomial time method based on $\ell_{1,2}$-group regularized logistic regression recovers a game, whose Nash equilibria are the $\epsilon$-Nash equilibria of the game from which the data was generated (true game), in $\mathcal{O}(m^4 d^4 \log (pd))$ samples of strategy profiles --- where $m$ is the maximum number of pure strategies of a player, $p$ is the number of players, and $d$ is the maximum degree of the game graph. Under slightly more stringent separability conditions on the payoff matrices of the true game, we show that our method learns a game with the exact same Nash equilibria as the true game. We also show that $\Omega(d \log (pm))$ samples are necessary for any method to consistently recover a game, with the same Nash-equilibria as the true game, from observations of strategic interactions. We verify our theoretical results through simulation experiments.