 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sequential Contexts using Transformer for 3D Hand Pose Estimation
Paper and Code
Jun 01, 2022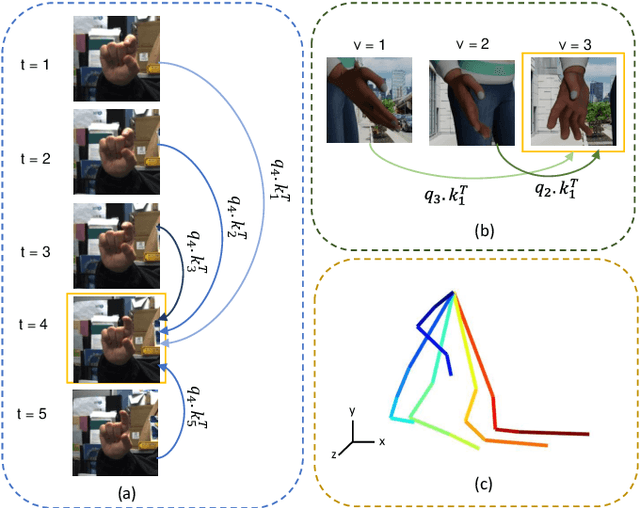
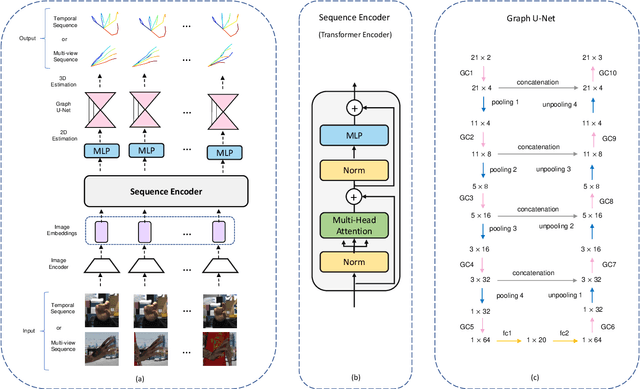
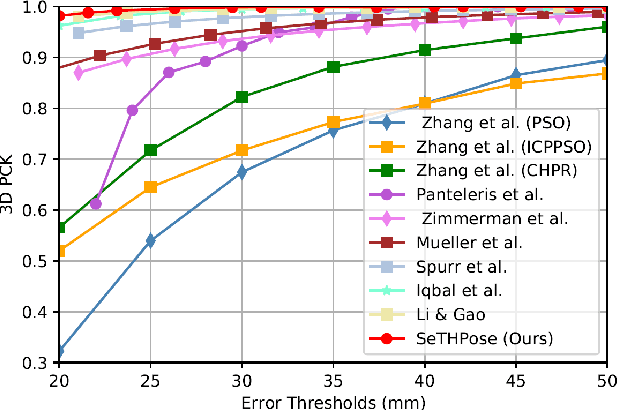

3D hand pose estimation (HPE) is the process of locating the joints of the hand in 3D from any visual input. HPE has recently received an increased amount of attention due to its key role in a variety of human-computer interaction applications. Recent HPE methods have demonstrated the advantages of employing videos or multi-view images, allowing for more robust HPE systems. Accordingly, in this study, we propose a new method to perform Sequential learning with Transformer for Hand Pose (SeTHPose) estimation. Our SeTHPose pipeline begins by extracting visual embeddings from individual hand images. We then use a transformer encoder to learn the sequential context along time or viewing angles and generate accurate 2D hand joint locations. Then, a graph convolutional neural network with a U-Net configuration is used to convert the 2D hand joint locations to 3D poses. Our experiments show that SeTHPose performs well on both hand sequence varieties, temporal and angular. Also, SeTHPose outperforms other methods in the field to achieve new state-of-the-art results on two public available sequential datasets, STB and MuViHand.