 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robot Activities from First-Person Human Videos Using Convolutional Future Regression
Paper and Code
Jul 24, 2017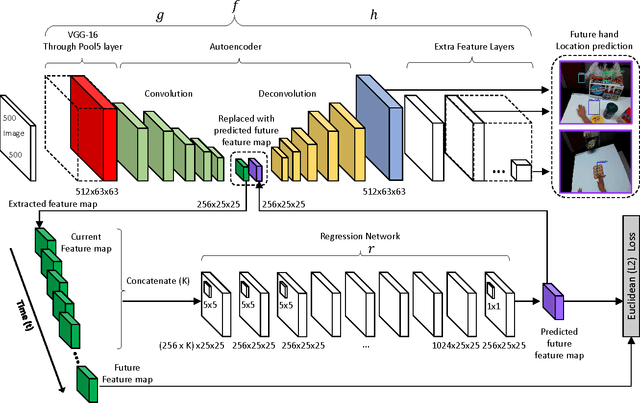
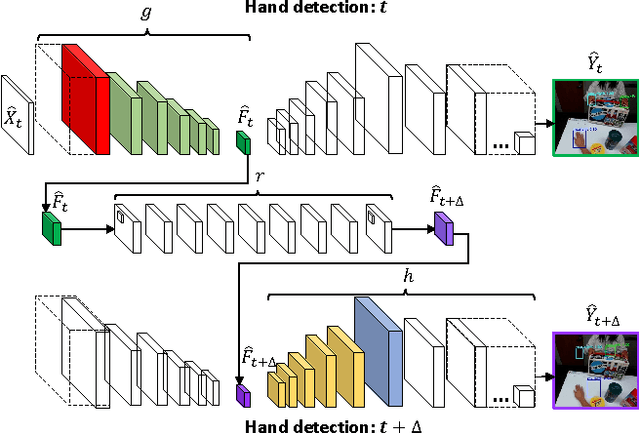
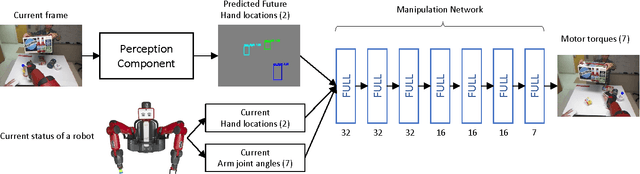

We design a new approach that allows robot learning of new activities from unlabeled human example videos. Given videos of humans executing the same activity from a human's viewpoint (i.e., first-person videos), our objective is to make the robot learn the temporal structure of the activity as its future regression network, and learn to transfer such model for its own motor execution. We present a new deep learning model: We extend the state-of-the-art convolutional object detection network for the representation/estimation of human hands in training videos, and newly introduce the concept of using a fully convolutional network to regress (i.e., predict) the intermediate scene representation corresponding to the future frame (e.g., 1-2 seconds later). Combining these allows direct prediction of future locations of human hands and objects, which enables the robot to infer the motor control plan using our manipulation network. We experimentally confirm that our approach makes learning of robot activities from unlabeled human interaction videos possible, and demonstrate that our robot is able to execute the learned collaborative activities in real-time directly based on its camera input.