 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representation for Bayesian Optimization with Collision-free Regularization
Paper and Code
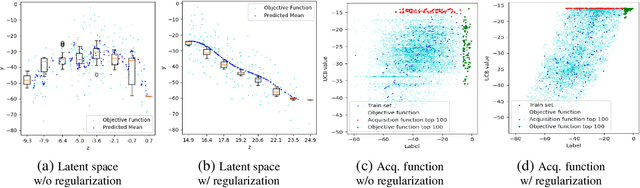
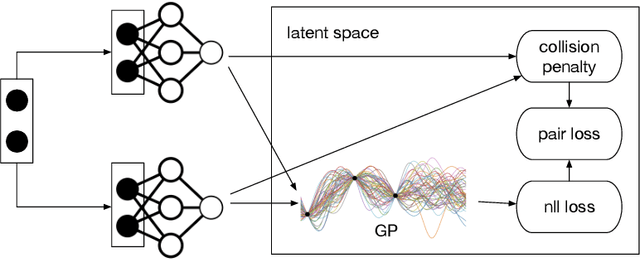
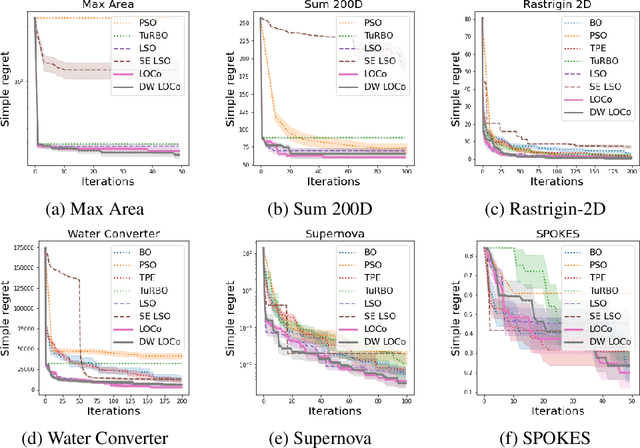
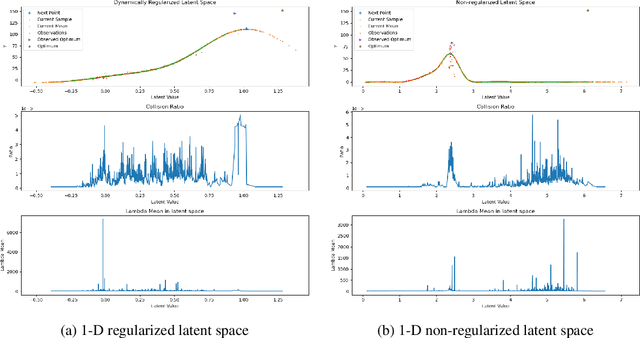
Bayesian optimization has been challenged by datasets with large-scale, high-dimensional, and non-stationary characteristics, which are common in real-world scenarios. Recent works attempt to handle such input by applying neural networks ahead of the classical Gaussian process to learn a latent representation. We show that even with proper network design, such learned representation often leads to collision in the latent space: two points with significantly different observations collide in the learned latent space, leading to degraded optimization performance. To address this issue, we propose LOCo, an efficient deep Bayesian optimization framework which employs a novel regularizer to reduce the collision in the learned latent space and encourage the mapping from the latent space to the objective value to be Lipschitz continuous. LOCo takes in pairs of data points and penalizes those too close in the latent space compared to their target space distance. We provide a rigorous theoretical justification for LOCo by inspecting the regret of this dynamic-embedding-based Bayesian optimization algorithm, where the neural network is iteratively retrained with the regularizer. Our empirical results demonstrate the effectiveness of LOCo on several synthetic and real-world benchmark Bayesian optimization tasks.