Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Preconditioners on Lie Groups
Paper and Code
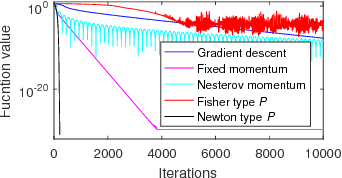
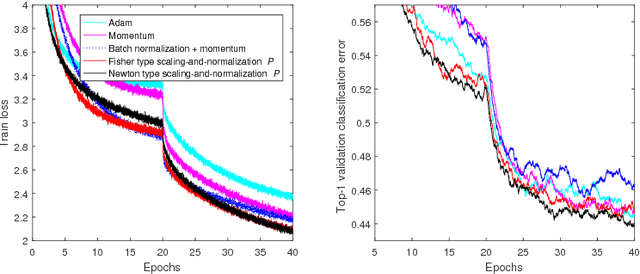
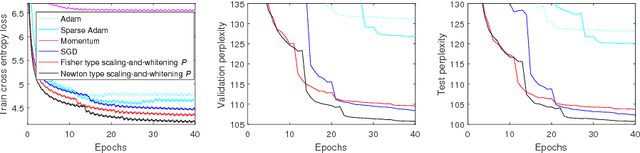
We study two types of preconditioners and preconditioned stochastic gradient descent (SGD) methods in a unified framework. We call the first one the Newton type due to its close relationship to Newton method, and the second one the Fisher type as its preconditioner is closely related to the inverse of Fisher information matrix. Both preconditioners can be derived from one framework, and efficiently learned on any matrix Lie groups designated by the user using natural or relative gradient descent. Many existing preconditioners and methods are special cases of either the Newton type or the Fisher type ones. Experimental results on relatively large scale machine learning problems are reported for performance study.
View paper on