 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Music Representations with wav2vec 2.0
Paper and Code
Oct 27, 2022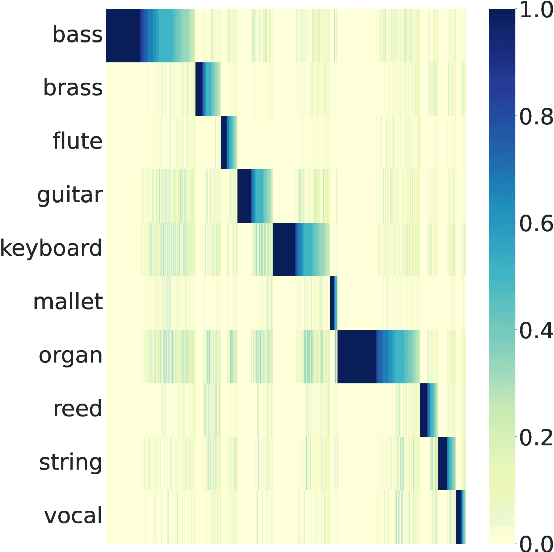
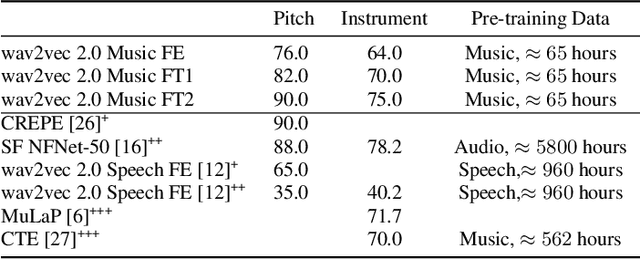
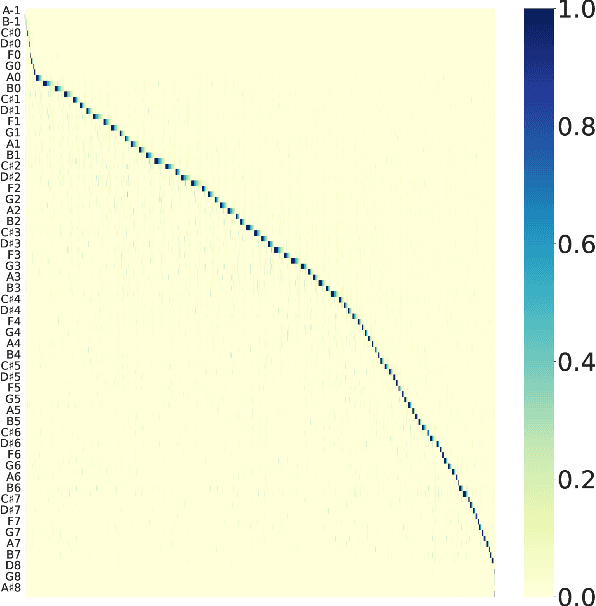
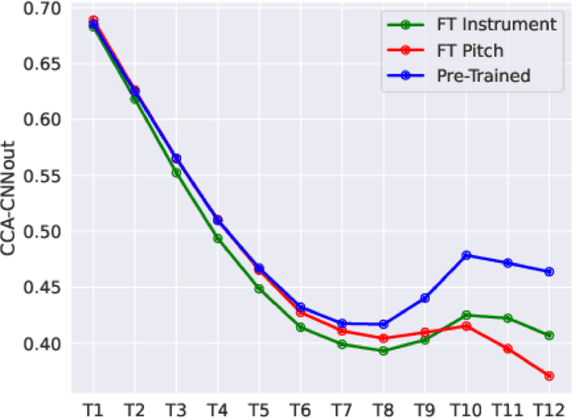
Learning music representations that are general-purpose offers the flexibility to finetune several downstream tasks using smaller datasets. The wav2vec 2.0 speech representation model showed promising results in many downstream speech tasks, but has been less effective when adapted to music. In this paper, we evaluate whether pre-training wav2vec 2.0 directly on music data can be a better solution instead of finetuning the speech model. We illustrate that when pre-training on music data, the discrete latent representations are able to encode the semantic meaning of musical concepts such as pitch and instrument. Our results show that finetuning wav2vec 2.0 pre-trained on music data allows us to achieve promising results on music classification tasks that are competitive with prior work on audio representations. In addition, the results are superior to the pre-trained model on speech embeddings, demonstrating that wav2vec 2.0 pre-trained on music data can be a promising music representation model.