 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More From Less: Towards Strengthening Weak Supervision for Ad-Hoc Retrieval
Paper and Code
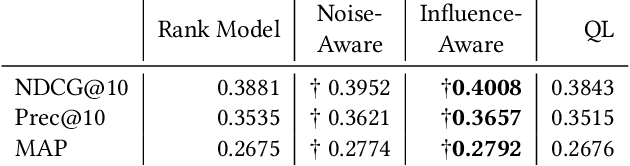
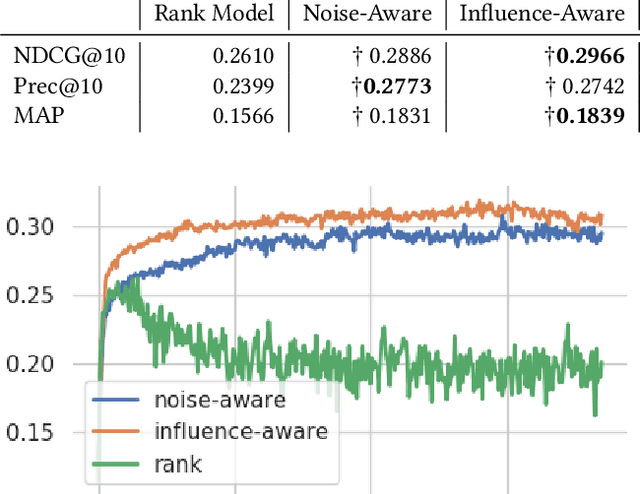
The limited availability of ground truth relevance labels has been a major impediment to the application of supervised methods to ad-hoc retrieval. As a result, unsupervised scoring methods, such as BM25, remain strong competitors to deep learning techniques which have brought on dramatic improvements in other domains, such as computer vision and natural language processing. Recent works have shown that it is possible to take advantage of the performance of these unsupervised methods to generate training data for learning-to-rank models. The key limitation to this line of work is the size of the training set required to surpass the performance of the original unsupervised method, which can be as large as $10^{13}$ training examples. Building on these insights, we propose two methods to reduce the amount of training data required. The first method takes inspiration from crowdsourcing, and leverages multiple unsupervised rankers to generate soft, or noise-aware, training labels. The second identifies harmful, or mislabeled, training examples and removes them from the training set. We show that our methods allow us to surpass the performance of the unsupervised baseline with far fewer training examples than previous works.