Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Randomly Initialized Neural Network Features
Paper and Code
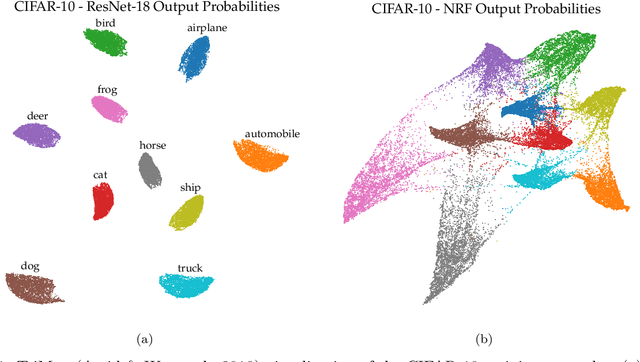
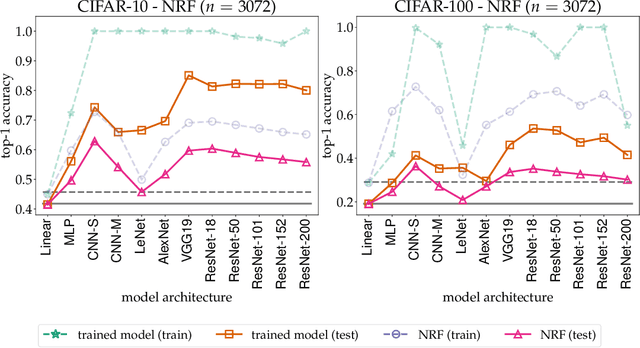
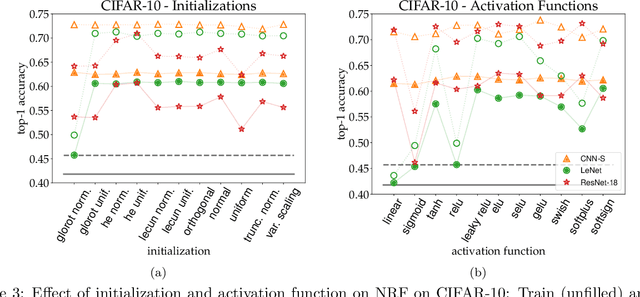
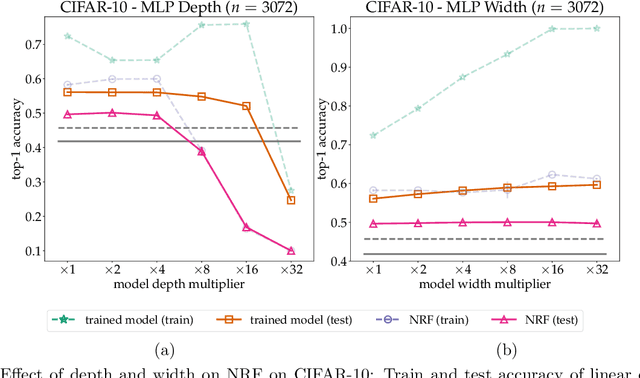
We present the surprising result that randomly initialized neural networks are good feature extractors in expectation. These random features correspond to finite-sample realizations of what we call Neural Network Prior Kernel (NNPK), which is inherently infinite-dimensional. We conduct ablations across multiple architectures of varying sizes as well as initializations and activation functions. Our analysis suggests that certain structures that manifest in a trained model are already present at initialization. Therefore, NNPK may provide further insight into why neural networks are so effective in learning such structures.
View paper on