 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Positive and Unlabeled Data with Arbitrary Positive Shift
Paper and Code
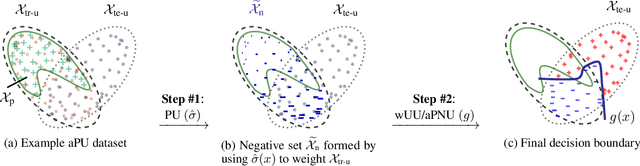
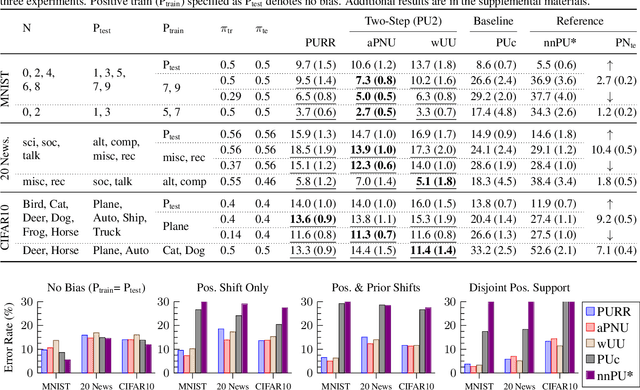
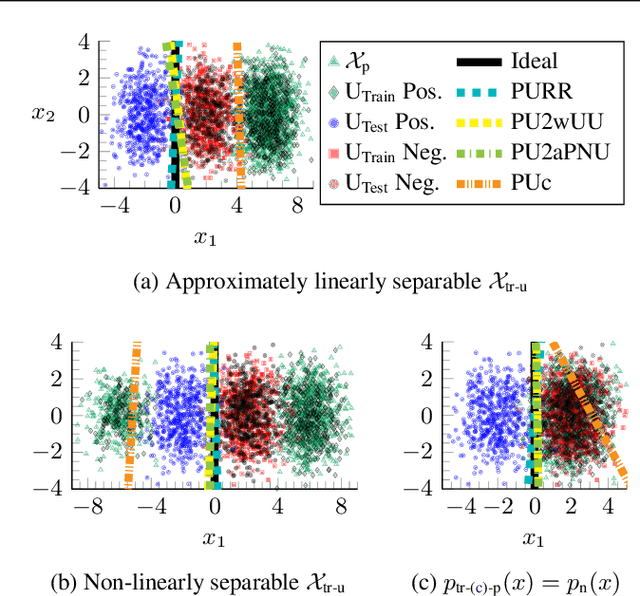
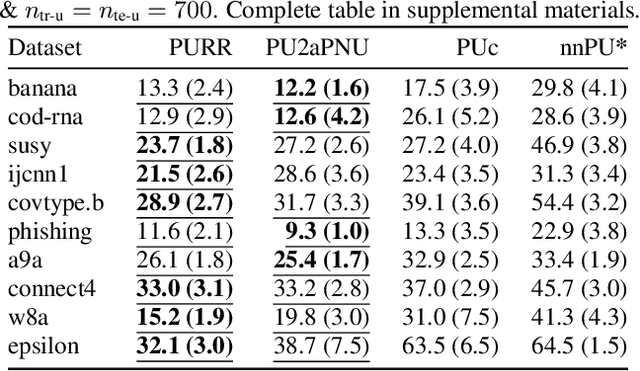
Positive-unlabeled (PU) learning trains a binary classifier using only positive and unlabeled data. A common simplifying assumption is that the positive data is representative of the target positive class. This assumption is often violated in practice due to time variation, domain shift, or adversarial concept drift. This paper shows that PU learning is possible even with arbitrarily non-representative positive data when provided unlabeled datasets from the source and target distributions. Our key insight is that only the negative class's distribution need be fixed. We propose two methods to learn under such arbitrary positive bias. The first couples negative-unlabeled (NU) learning with unlabeled-unlabeled (UU) learning while the other uses a novel recursive risk estimator robust to positive shift. Experimental results demonstrate our methods' effectiveness across numerous real-world datasets and forms of positive data bias, including disjoint positive class-conditional supports.