 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from few examples with nonlinear feature maps
Paper and Code
Mar 31, 2022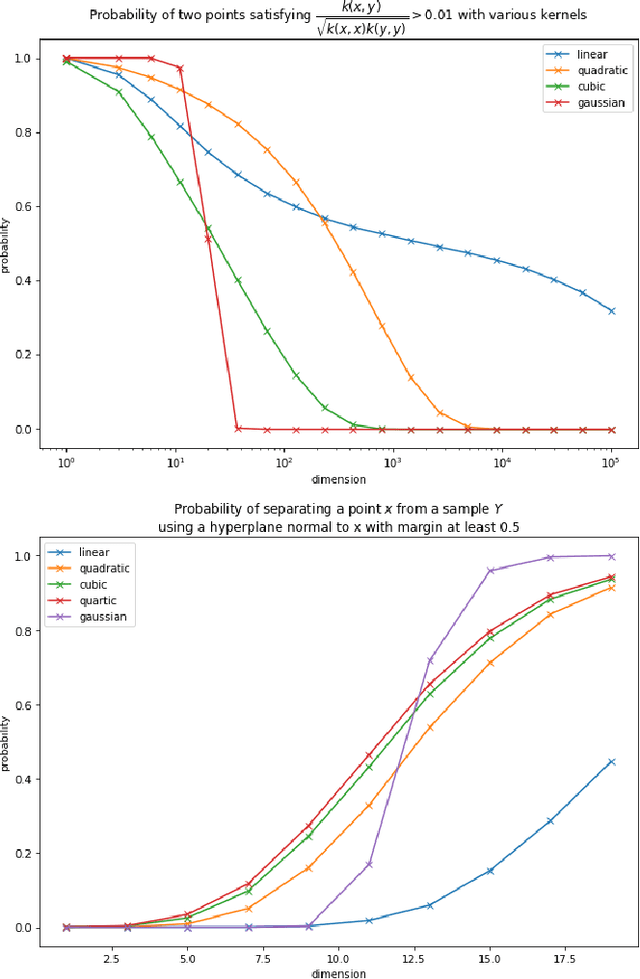
In this work we consider the problem of data classification in post-classical settings were the number of training examples consists of mere few data points. We explore the phenomenon and reveal key relationships between dimensionality of AI model's feature space, non-degeneracy of data distributions, and the model's generalisation capabilities. The main thrust of our present analysis is on the influence of nonlinear feature transformations mapping original data into higher- and possibly infinite-dimensional spaces on the resulting model's generalisation capabilities. Subject to appropriate assumptions, we establish new relationships between intrinsic dimensions of the transformed data and the probabilities to learn successfully from few presentations.