 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Data with Noisy Labels Using Temporal Self-Ensemble
Paper and Code
Jul 21, 2022


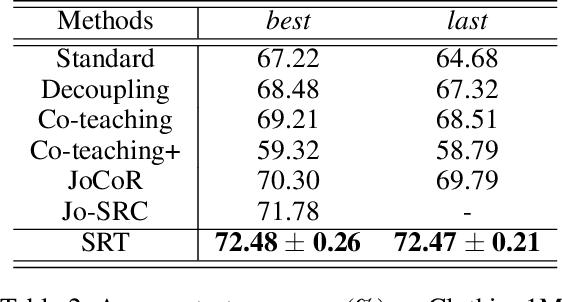
There are inevitably many mislabeled data in real-world datasets. Because deep neural networks (DNNs) have an enormous capacity to memorize noisy labels, a robust training scheme is required to prevent labeling errors from degrading the generalization performance of DNNs. Current state-of-the-art methods present a co-training scheme that trains dual networks using samples associated with small losses. In practice, however, training two networks simultaneously can burden computing resources. In this study, we propose a simple yet effective robust training scheme that operates by training only a single network. During training, the proposed method generates temporal self-ensemble by sampling intermediate network parameters from the weight trajectory formed by stochastic gradient descent optimization. The loss sum evaluated with these self-ensembles is used to identify incorrectly labeled samples. In parallel, our method generates multi-view predictions by transforming an input data into various forms and considers their agreement to identify incorrectly labeled samples. By combining the aforementioned metrics, we present the proposed {\it self-ensemble-based robust training} (SRT) method, which can filter the samples with noisy labels to reduce their influence on training. Experiments on widely-used public datasets demonstrate that the proposed method achieves a state-of-the-art performance in some categories without training the dual networks.