 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from data in the mixed adversarial non-adversarial case: Finding the helpers and ignoring the trolls
Paper and Code
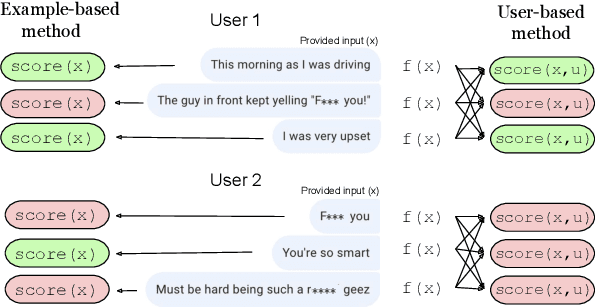
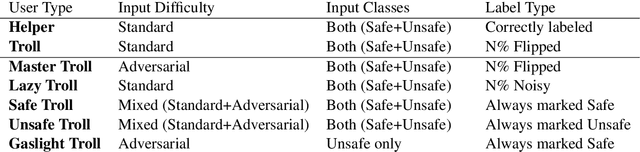
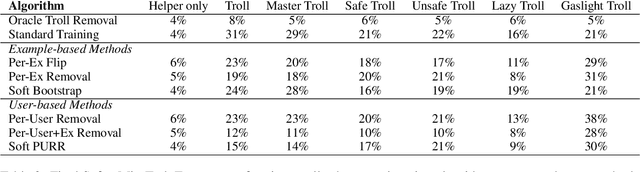
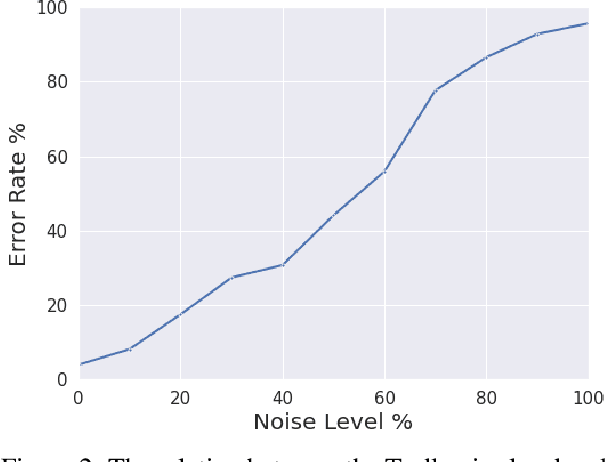
The promise of interaction between intelligent conversational agents and humans is that models can learn from such feedback in order to improve. Unfortunately, such exchanges in the wild will not always involve human utterances that are benign or of high quality, and will include a mixture of engaged (helpers) and unengaged or even malicious users (trolls). In this work we study how to perform robust learning in such an environment. We introduce a benchmark evaluation, SafetyMix, which can evaluate methods that learn safe vs. toxic language in a variety of adversarial settings to test their robustness. We propose and analyze several mitigating learning algorithms that identify trolls either at the example or at the user level. Our main finding is that user-based methods, that take into account that troll users will exhibit adversarial behavior across multiple examples, work best in a variety of settings on our benchmark. We then test these methods in a further real-life setting of conversations collected during deployment, with similar results.