 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fashion Compatibility from In-the-wild Images
Paper and Code
Jun 13, 2022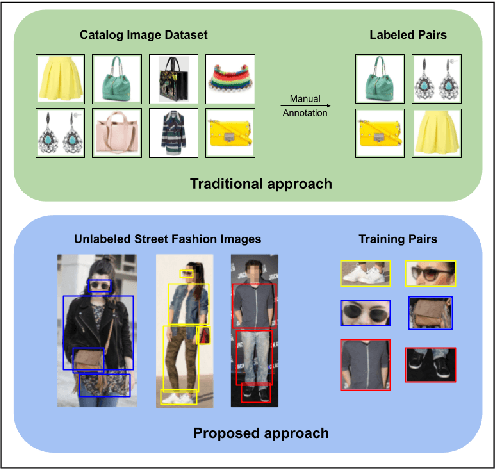

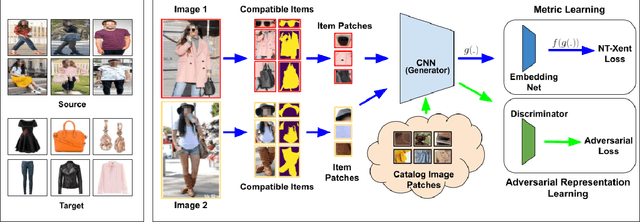

Complementary fashion recommendation aims at identifying items from different categories (e.g. shirt, footwear, etc.) that "go well together" as an outfit. Most existing approaches learn representation for this task using labeled outfit datasets containing manually curated compatible item combinations. In this work, we propose to learn representations for compatibility prediction from in-the-wild street fashion images through self-supervised learning by leveraging the fact that people often wear compatible outfits. Our pretext task is formulated such that the representations of different items worn by the same person are closer compared to those worn by other people. Additionally, to reduce the domain gap between in-the-wild and catalog images during inference, we introduce an adversarial loss that minimizes the difference in feature distribution between the two domains. We conduct our experiments on two popular fashion compatibility benchmarks - Polyvore and Polyvore-Disjoint outfits, and outperform existing self-supervised approaches, particularly significant in cross-dataset setting where training and testing images are from different sources.