 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Framework for US Signals Super-resolution
Paper and Code
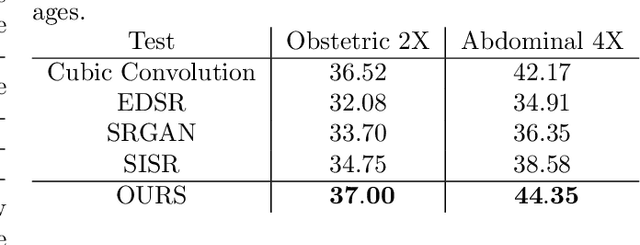
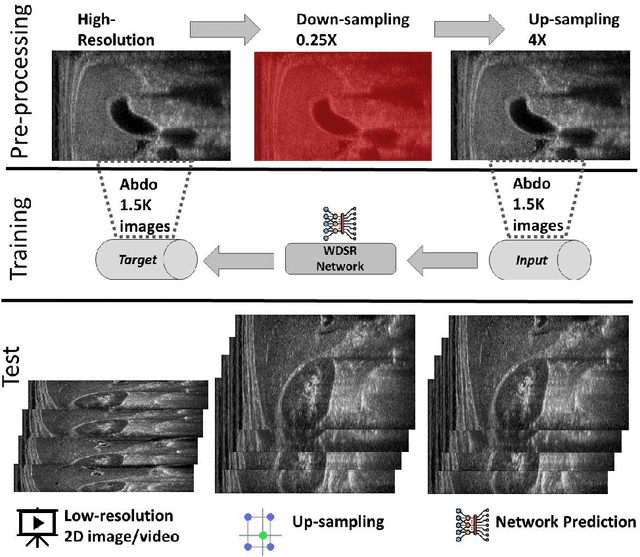

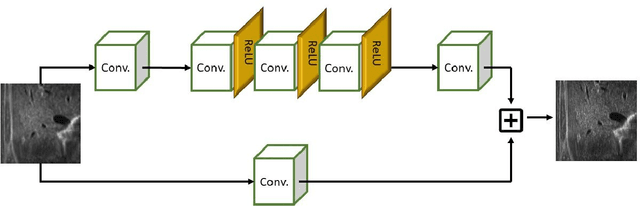
We propose a novel deep-learning framework for super-resolution ultrasound images and videos in terms of spatial resolution and line reconstruction. We up-sample the acquired low-resolution image through a vision-based interpolation method; then, we train a learning-based model to improve the quality of the up-sampling. We qualitatively and quantitatively test our model on different anatomical districts (e.g., cardiac, obstetric) images and with different up-sampling resolutions (i.e., 2X, 4X). Our method improves the PSNR median value with respect to SOTA methods of $1.7\%$ on obstetric 2X raw images, $6.1\%$ on cardiac 2X raw images, and $4.4\%$ on abdominal raw 4X images; it also improves the number of pixels with a low prediction error of $9.0\%$ on obstetric 4X raw images, $5.2\%$ on cardiac 4X raw images, and $6.2\%$ on abdominal 4X raw images. The proposed method is then applied to the spatial super-resolution of 2D videos, by optimising the sampling of lines acquired by the probe in terms of the acquisition frequency. Our method specialises trained networks to predict the high-resolution target through the design of the network architecture and the loss function, taking into account the anatomical district and the up-sampling factor and exploiting a large ultrasound data set. The use of deep learning on large data sets overcomes the limitations of vision-based algorithms that are general and do not encode the characteristics of the data. Furthermore, the data set can be enriched with images selected by medical experts to further specialise the individual networks. Through learning and high-performance computing, our super-resolution is specialised to different anatomical districts by training multiple networks. Furthermore, the computational demand is shifted to centralised hardware resources with a real-time execution of the network's prediction on local devices.