 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Articulated Motions From Visual Demonstration
Paper and Code
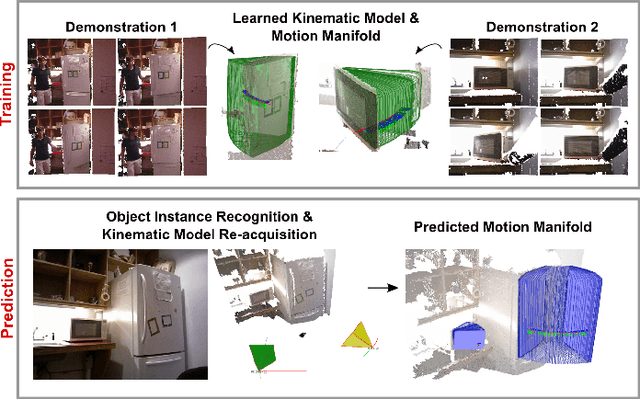
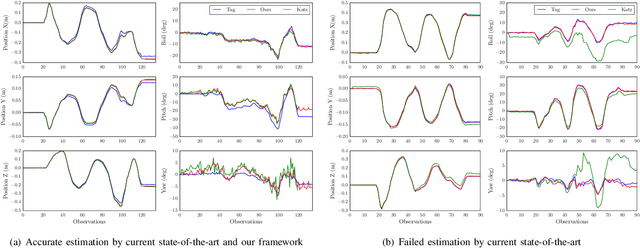
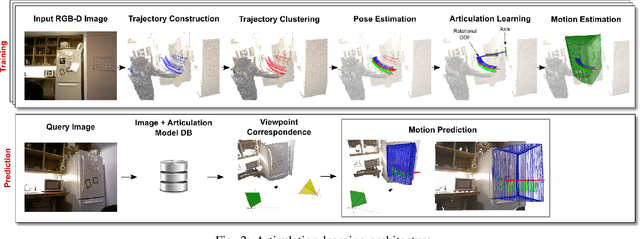
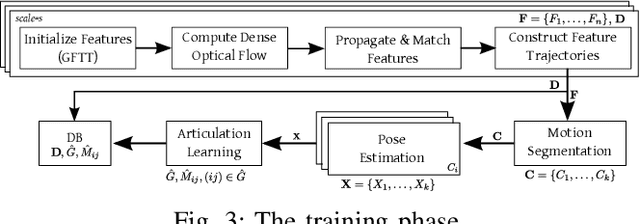
Many functional elements of human homes and workplaces consist of rigid components which are connected through one or more sliding or rotating linkages. Examples include doors and drawers of cabinets and appliances; laptops; and swivel office chairs. A robotic mobile manipulator would benefit from the ability to acquire kinematic models of such objects from observation. This paper describes a method by which a robot can acquire an object model by capturing depth imagery of the object as a human moves it through its range of motion. We envision that in future, a machine newly introduced to an environment could be shown by its human user the articulated objects particular to that environment, inferring from these "visual demonstrations" enough information to actuate each object independently of the user. Our method employs sparse (markerless) feature tracking, motion segmentation, component pose estimation, and articulation learning; it does not require prior object models. Using the method, a robot can observe an object being exercised, infer a kinematic model incorporating rigid, prismatic and revolute joints, then use the model to predict the object's motion from a novel vantage point. We evaluate the method's performance, and compare it to that of a previously published technique, for a variety of household objects.