 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Word-Level Language Model with Sentence-Level Noise Contrastive Estimation for Contextual Sentence Probability Estimation
Paper and Code
Mar 14, 2021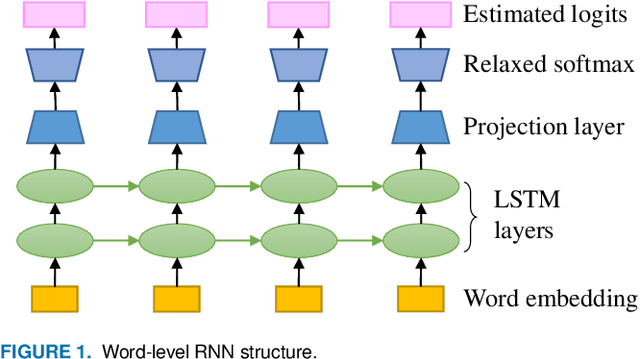
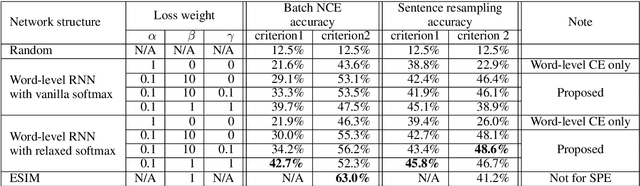
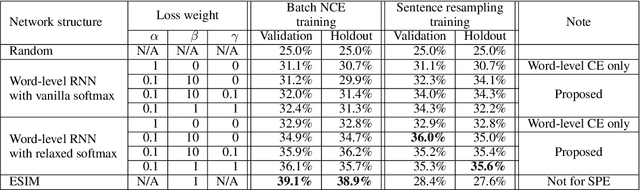
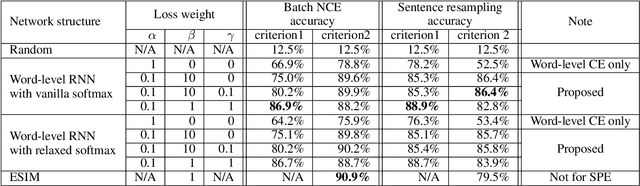
Inferring the probability distribution of sentences or word sequences is a key process in natural language processing. While word-level language models (LMs) have been widely adopted for computing the joint probabilities of word sequences, they have difficulty in capturing a context long enough for sentence probability estimation (SPE). To overcome this, recent studies introduced training methods using sentence-level noise-contrastive estimation (NCE) with recurrent neural networks (RNNs). In this work, we attempt to extend it for contextual SPE, which aims to estimate a conditional sentence probability given a previous text. The proposed NCE samples negative sentences independently of a previous text so that the trained model gives higher probabilities to the sentences that are more consistent with \textcolor{blue}{the} context. We apply our method to a simple word-level RNN LM to focus on the effect of the sentence-level NCE training rather than on the network architecture. The quality of estimation was evaluated against multiple-choice cloze-style questions including both human and automatically generated questions. The experimental results show that the proposed method improved the SPE quality for the word-level RNN LM.