 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Knowledge Extraction from Deep Convolutional Networks
Paper and Code
Mar 19, 2020
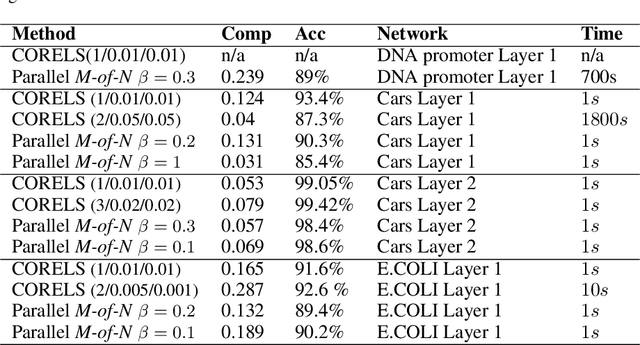


Knowledge extraction is used to convert neural networks into symbolic descriptions with the objective of producing more comprehensible learning models. The central challenge is to find an explanation which is more comprehensible than the original model while still representing that model faithfully. The distributed nature of deep networks has led many to believe that the hidden features of a neural network cannot be explained by logical descriptions simple enough to be comprehensible. In this paper, we propose a novel layerwise knowledge extraction method using M-of-N rules which seeks to obtain the best trade-off between the complexity and accuracy of rules describing the hidden features of a deep network. We show empirically that this approach produces rules close to an optimal complexity-error tradeoff. We apply this method to a variety of deep networks and find that in the internal layers we often cannot find rules with a satisfactory complexity and accuracy, suggesting that rule extraction as a general purpose method for explaining the internal logic of a neural network may be impossible. However, we also find that the softmax layer in Convolutional Neural Networks and Autoencoders using either tanh or relu activation functions is highly explainable by rule extraction, with compact rules consisting of as little as 3 units out of 128 often reaching over 99% accuracy. This shows that rule extraction can be a useful component for explaining parts (or modules) of a deep neural network.