 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Simplex Position Model: High Dimensional Multi-view Clustering with Uncertainty Quantification
Paper and Code
Mar 21, 2019
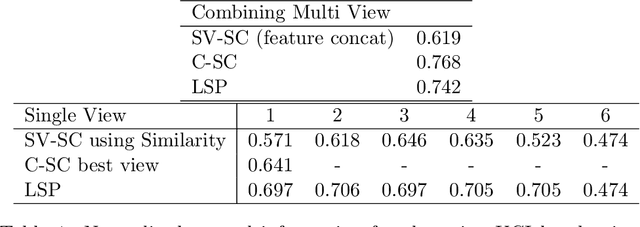

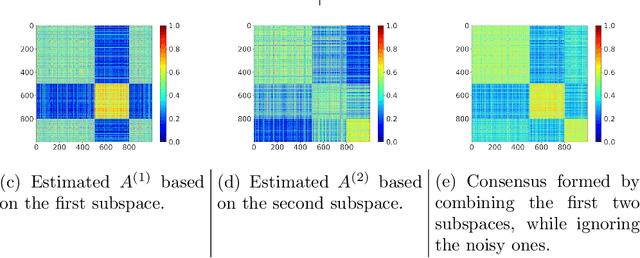
High dimensional data often contain multiple facets, and several clustering patterns (views) can co-exist under different feature subspaces. While multi-view clustering algorithms were proposed, the uncertainty quantification remains difficult --- a particular challenge is in the high complexity of estimating the cluster assignment probability under each view, or/and to efficiently share information across views. In this article, we propose an empirical Bayes approach --- viewing the similarity matrices generated over subspaces as rough first-stage estimates for co-assignment probabilities, in its Kullback-Leibler neighborhood we obtain a refined low-rank soft cluster graph, formed by the pairwise product of simplex coordinates. Interestingly, each simplex coordinate directly encodes the cluster assignment uncertainty. For multi-view clustering, we equip each similarity matrix with a mixed membership over a small number of latent views, leading to effective dimension reduction. With a high model flexibility, the estimation can be succinctly re-parameterized as a continuous optimization problem, hence enjoys gradient-based computation. Theory establishes the connection of this model to random cluster graph under multiple views. Compared to single-view clustering approaches, substantially more interpretable results are obtained when clustering brains from human traumatic brain injury study, using high-dimensional gene expression data. KEY WORDS: Co-regularized Clustering, Consensus, PAC-Bayes, Random Cluster Graph, Variable Selection