 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Zero-Shot Image Classification from Rich and Diverse Textual Descriptions
Paper and Code



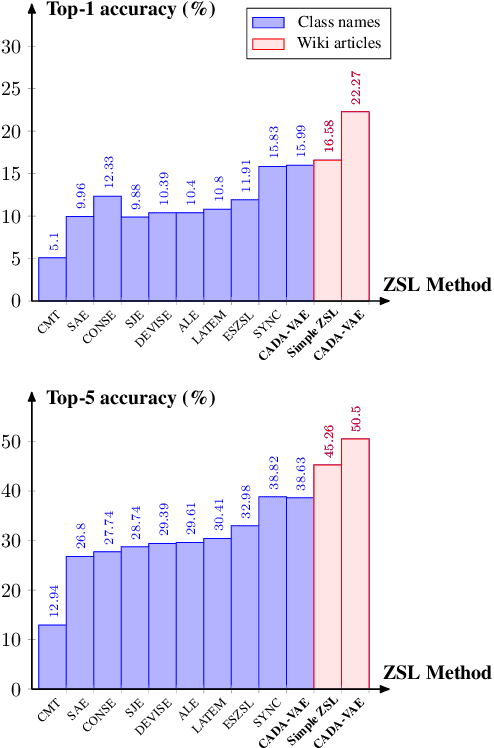
We study the impact of using rich and diverse textual descriptions of classes for zero-shot learning (ZSL) on ImageNet. We create a new dataset ImageNet-Wiki that matches each ImageNet class to its corresponding Wikipedia article. We show that merely employing these Wikipedia articles as class descriptions yields much higher ZSL performance than prior works. Even a simple model using this type of auxiliary data outperforms state-of-the-art models that rely on standard features of word embedding encodings of class names. These results highlight the usefulness and importance of textual descriptions for ZSL, as well as the relative importance of auxiliary data type compared to algorithmic progress. Our experimental results also show that standard zero-shot learning approaches generalize poorly across categories of classes.