Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Learning with Less RAM via Randomization
Paper and Code
Mar 19, 2013

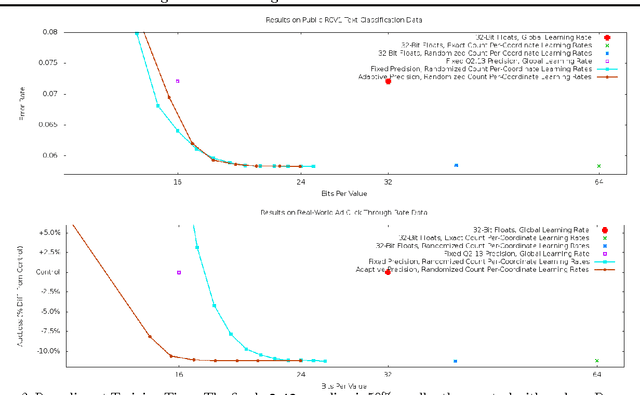
We reduce the memory footprint of popular large-scale online learning methods by projecting our weight vector onto a coarse discrete set using randomized rounding. Compared to standard 32-bit float encodings, this reduces RAM usage by more than 50% during training and by up to 95% when making predictions from a fixed model, with almost no loss in accuracy. We also show that randomized counting can be used to implement per-coordinate learning rates, improving model quality with little additional RAM. We prove these memory-saving methods achieve regret guarantees similar to their exact variants. Empirical evaluation confirms excellent performance, dominating standard approaches across memory versus accuracy tradeoffs.
* Extended version of ICML 2013 paper
View paper on