 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Event Forecasters
Paper and Code
Jun 15, 2024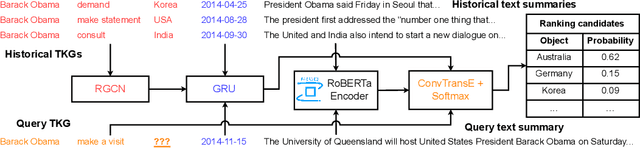
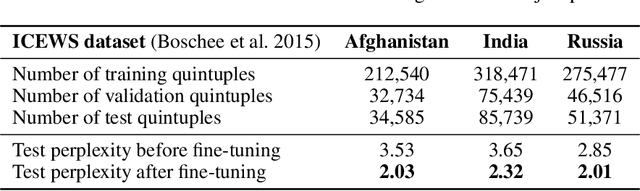


Key elements of human events are extracted as quadruples that consist of subject, relation, object, and timestamp. This representation can be extended to a quintuple by adding a fifth element: a textual summary that briefly describes the event. These quadruples or quintuples, when organized within a specific domain, form a temporal knowledge graph (TKG). Current learning frameworks focus on a few TKG-related tasks, such as predicting an object given a subject and a relation or forecasting the occurrences of multiple types of events (i.e., relation) in the next time window. They typically rely on complex structural and sequential models like graph neural networks (GNNs) and recurrent neural networks (RNNs) to update intermediate embeddings. However, these methods often neglect the contextual information inherent in each quintuple, which can be effectively captured through concise textual descriptions. In this paper, we investigate how large language models (LLMs) can streamline the design of TKG learning frameworks while maintaining competitive accuracy in prediction and forecasting tasks. We develop multiple prompt templates to frame the object prediction (OP) task as a standard question-answering (QA) task, suitable for instruction fine-tuning with an encoder-decoder generative LLM. For multi-event forecasting (MEF), we design simple yet effective prompt templates for each TKG quintuple. This novel approach removes the need for GNNs and RNNs, instead utilizing an encoder-only LLM to generate fixed intermediate embeddings, which are subsequently processed by a prediction head with a self-attention mechanism to forecast potential future relations. Extensive experiments on multiple real-world datasets using various evaluation metrics validate the effectiveness and robustness of our approach.