 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Need Inductive Biases to Count Inductively
Paper and Code

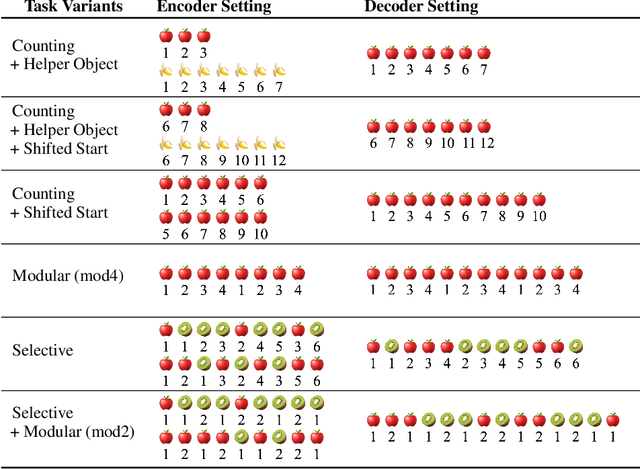

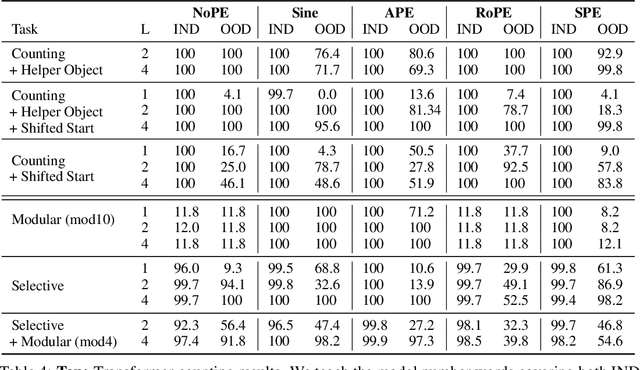
Counting is a fundamental example of generalization, whether viewed through the mathematical lens of Peano's axioms defining the natural numbers or the cognitive science literature for children learning to count. The argument holds for both cases that learning to count means learning to count infinitely. While few papers have tried to distill transformer "reasoning" to the simplest case of counting, investigating length generalization does occur throughout the literature. In the "train short, test long" paradigm of NLP, length refers to the training sentence length. In formal language recognition, length refers to the input sequence length, or the maximum stack size induced by a pushdown automata. In general problem solving, length refers to the number of hops in a deductive reasoning chain or the recursion depth. For all cases, counting is central to task success. And crucially, generalizing counting inductively is central to success on OOD instances. This work provides extensive empirical results on training language models to count. We experiment with architectures ranging from RNNs, Transformers, State-Space Models and RWKV. We present carefully-designed task formats, auxiliary tasks and positional embeddings to avoid limitations in generalization with OOD-position and OOD-vocabulary. We find that while traditional RNNs trivially achieve inductive counting, Transformers have to rely on positional embeddings to count out-of-domain. As counting is the basis for many arguments concerning the expressivity of Transformers, our finding calls for the community to reexamine the application scope of primitive functions defined in formal characterizations. Finally, modern RNNs also largely underperform traditional RNNs in generalizing counting inductively. We discuss how design choices that enable parallelized training of modern RNNs cause them to lose merits of a recurrent nature.