 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model for Text Analytic in Cybersecurity
Paper and Code
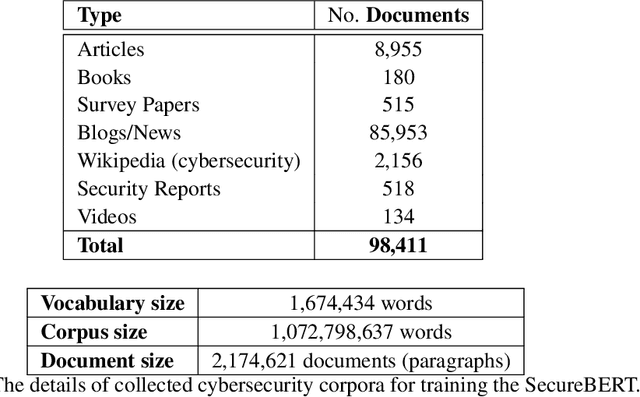
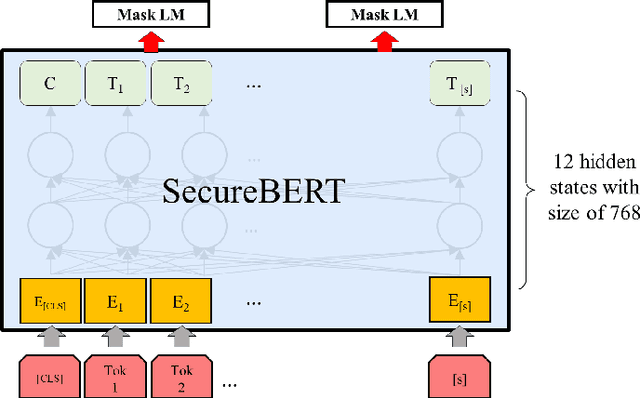
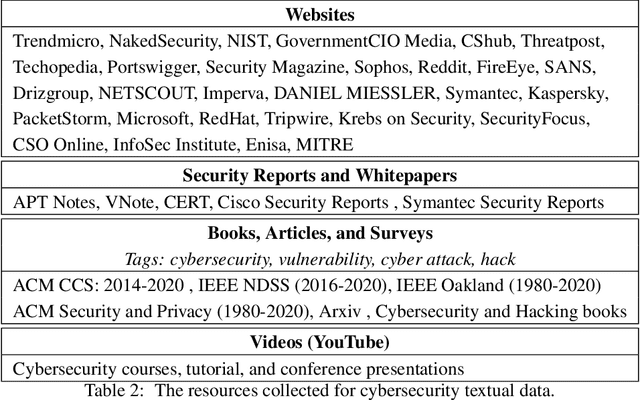
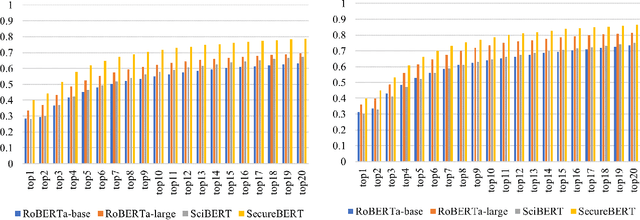
NLP is a form of artificial intelligence and machine learning concerned with a computer or machine's ability to understand and interpret human language. Language models are crucial in text analytics and NLP since they allow computers to interpret qualitative input and convert it to quantitative data that they can use in other tasks. In essence, in the context of transfer learning, language models are typically trained on a large generic corpus, referred to as the pre-training stage, and then fine-tuned to a specific underlying task. As a result, pre-trained language models are mostly used as a baseline model that incorporates a broad grasp of the context and may be further customized to be used in a new NLP task. The majority of pre-trained models are trained on corpora from general domains, such as Twitter, newswire, Wikipedia, and Web. Such off-the-shelf NLP models trained on general text may be inefficient and inaccurate in specialized fields. In this paper, we propose a cybersecurity language model called SecureBERT, which is able to capture the text connotations in the cybersecurity domain, and therefore could further be used in automation for many important cybersecurity tasks that would otherwise rely on human expertise and tedious manual efforts. SecureBERT is trained on a large corpus of cybersecurity text collected and preprocessed by us from a variety of sources in cybersecurity and the general computing domain. Using our proposed methods for tokenization and model weights adjustment, SecureBERT is not only able to preserve the understanding of general English as most pre-trained language models can do, but also effective when applied to text that has cybersecurity implications.