 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Does More Than Describe: On The Lack Of Figurative Speech in Text-To-Image Models
Paper and Code
Oct 19, 2022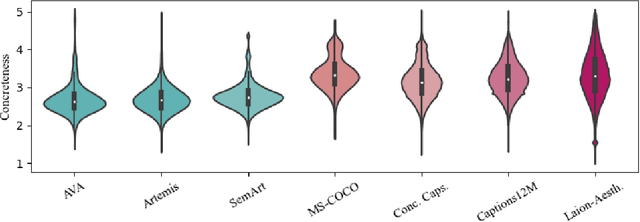
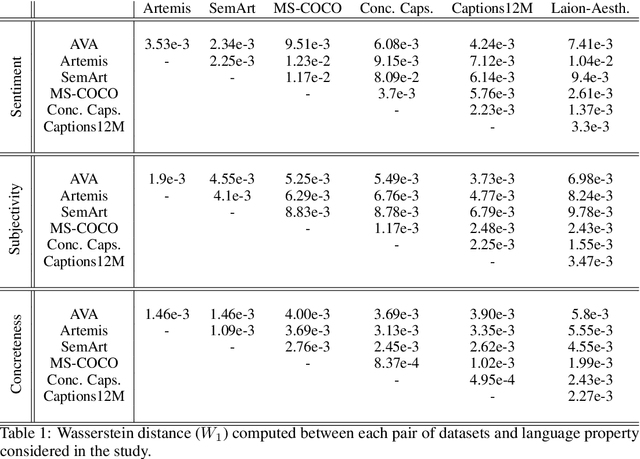


The impressive capacity shown by recent text-to-image diffusion models to generate high-quality pictures from textual input prompts has leveraged the debate about the very definition of art. Nonetheless, these models have been trained using text data collected from content-based labelling protocols that focus on describing the items and actions in an image but neglect any subjective appraisal. Consequently, these automatic systems need rigorous descriptions of the elements and the pictorial style of the image to be generated, otherwise failing to deliver. As potential indicators of the actual artistic capabilities of current generative models, we characterise the sentimentality, objectiveness and degree of abstraction of publicly available text data used to train current text-to-image diffusion models. Considering the sharp difference observed between their language style and that typically employed in artistic contexts, we suggest generative models should incorporate additional sources of subjective information in their training in order to overcome (or at least to alleviate) some of their current limitations, thus effectively unleashing a truly artistic and creative generation.