Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-depedent I-Vectors for LRE15
Paper and Code
Sep 29, 2017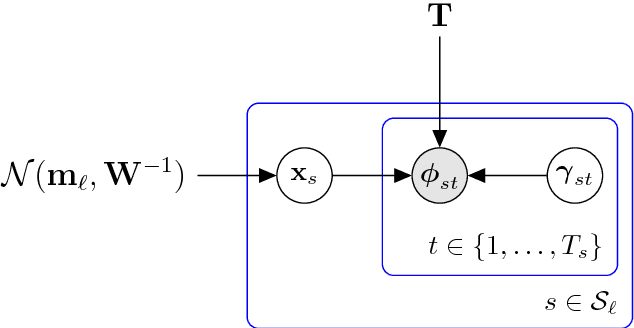
A standard recipe for spoken language recognition is to apply a Gaussian back-end to i-vectors. This ignores the uncertainty in the i-vector extraction, which could be important especially for short utterances. A recent paper by Cumani, Plchot and Fer proposes a solution to propagate that uncertainty into the backend. We propose an alternative method of propagating the uncertainty.
View paper on