 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMP: Learning a Motion Policy to Repeatedly Navigate in an Uncertain Environment
Paper and Code
Dec 03, 2020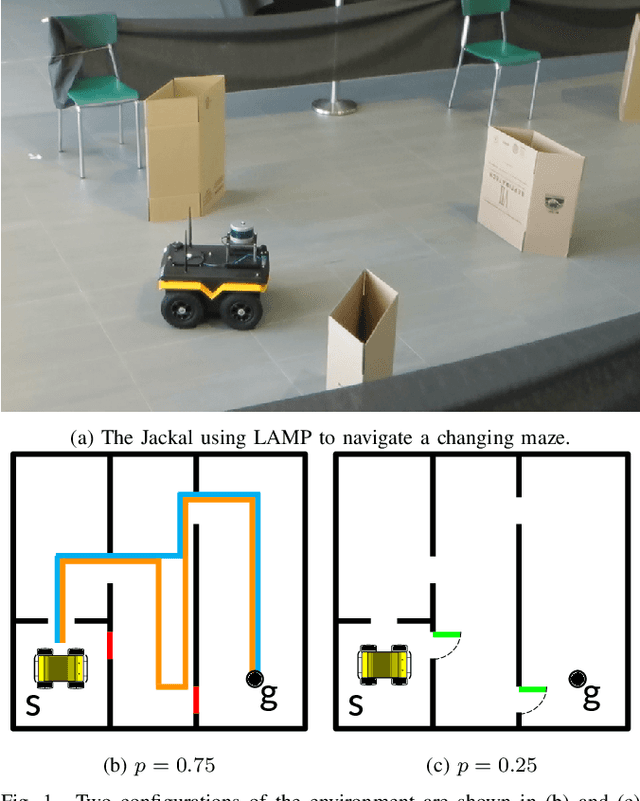
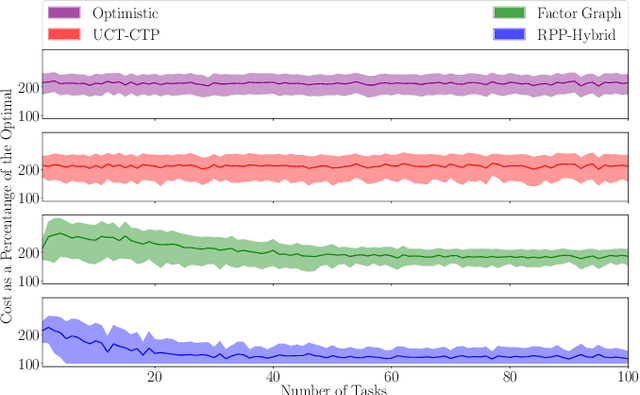
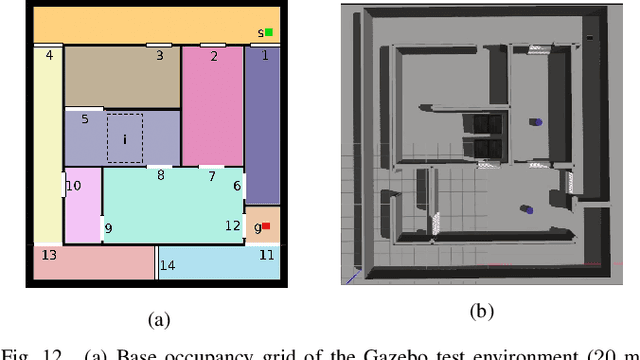
Mobile robots are often tasked with repeatedly navigating through an environment whose traversability changes over time. These changes may exhibit some hidden structure, which can be learned. Many studies consider reactive algorithms for online planning, however, these algorithms do not take advantage of the past executions of the navigation task for future tasks. In this paper, we formalize the problem of minimizing the total expected cost to perform multiple start-to-goal navigation tasks on a roadmap by introducing the Learned Reactive Planning Problem. We propose a method that captures information from past executions to learn a motion policy to handle obstacles that the robot has seen before. We propose the LAMP framework, which integrates the generated motion policy with an existing navigation stack. Finally, an extensive set of experiments in simulated and real-world environments show that the proposed method outperforms the state-of-the-art algorithms by 10% to 40% in terms of expected time to travel from start to goal. We also evaluate the robustness of the proposed method in the presence of localization and mapping errors on a real robot.