 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKvistur 2.0: a BiLSTM Compound Splitter for Icelandic
Paper and Code
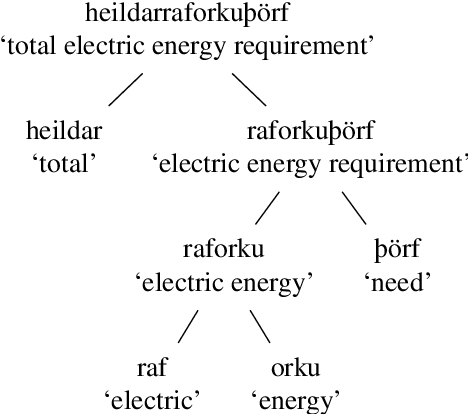
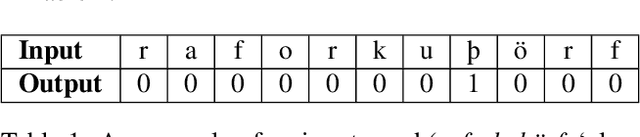
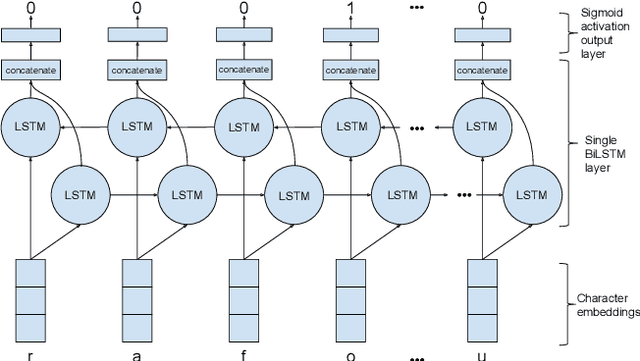
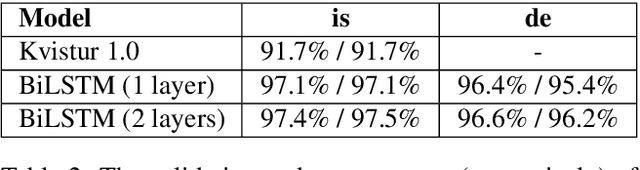
In this paper, we present a character-based BiLSTM model for splitting Icelandic compound words, and show how varying amounts of training data affects the performance of the model. Compounding is highly productive in Icelandic, and new compounds are constantly being created. This results in a large number of out-of-vocabulary (OOV) words, negatively impacting the performance of many NLP tools. Our model is trained on a dataset of 2.9 million unique word forms and their constituent structures from the Database of Icelandic Morphology. The model learns how to split compound words into two parts and can be used to derive the constituent structure of any word form. Knowing the constituent structure of a word form makes it possible to generate the optimal split for a given task, e.g., a full split for subword tokenization, or, in the case of part-of-speech tagging, splitting an OOV word until the largest known morphological head is found. The model outperforms other previously published methods when evaluated on a corpus of manually split word forms. This method has been integrated into Kvistur, an Icelandic compound word analyzer.