Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKUISAIL at SemEval-2020 Task 12: BERT-CNN for Offensive Speech Identification in Social Media
Paper and Code


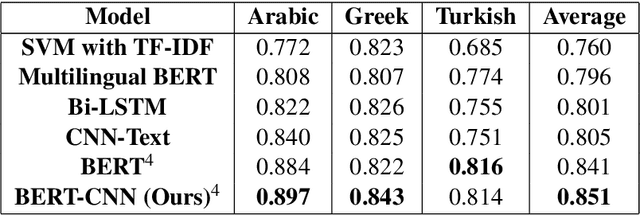
In this paper, we describe our approach to utilize pre-trained BERT models with Convolutional Neural Networks for sub-task A of the Multilingual Offensive Language Identification shared task (OffensEval 2020), which is a part of the SemEval 2020. We show that combining CNN with BERT is better than using BERT on its own, and we emphasize the importance of utilizing pre-trained language models for downstream tasks. Our system, ranked 4th with macro averaged F1-Score of 0.897 in Arabic, 4th with score of 0.843 in Greek, and 3rd with score of 0.814 in Turkish. Additionally, we present ArabicBERT, a set of pre-trained transformer language models for Arabic that we share with the community.
* to be published in the proceedings of the 14th International Workshop
on Semantic Evaluation (SemEval2020), Association for Computational
Linguistics (ACL)
View paper on