 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTCR: Improving Implicit Hate Detection with Knowledge Transfer driven Concept Refinement
Paper and Code
Oct 20, 2024
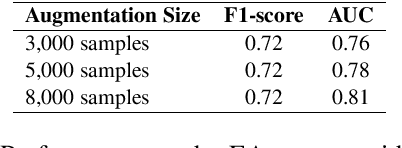
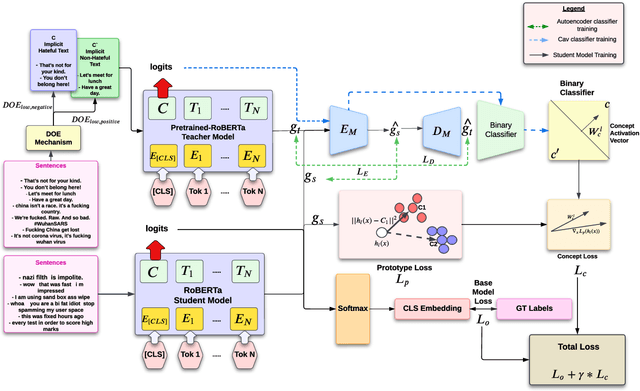
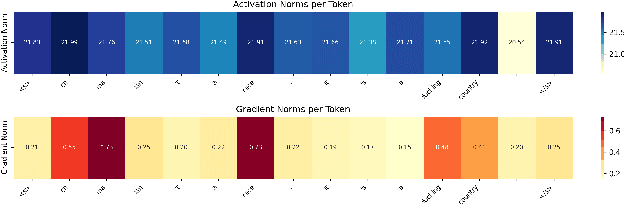
The constant shifts in social and political contexts, driven by emerging social movements and political events, lead to new forms of hate content and previously unrecognized hate patterns that machine learning models may not have captured. Some recent literature proposes the data augmentation-based techniques to enrich existing hate datasets by incorporating samples that reveal new implicit hate patterns. This approach aims to improve the model's performance on out-of-domain implicit hate instances. It is observed, that further addition of more samples for augmentation results in the decrease of the performance of the model. In this work, we propose a Knowledge Transfer-driven Concept Refinement method that distills and refines the concepts related to implicit hate samples through novel prototype alignment and concept losses, alongside data augmentation based on concept activation vectors. Experiments with several publicly available datasets show that incorporating additional implicit samples reflecting new hate patterns through concept refinement enhances the model's performance, surpassing baseline results while maintaining cross-dataset generalization capabilities.\footnote{DISCLAIMER: This paper contains explicit statements that are potentially offensive.}