 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKov: Transferable and Naturalistic Black-Box LLM Attacks using Markov Decision Processes and Tree Search
Paper and Code


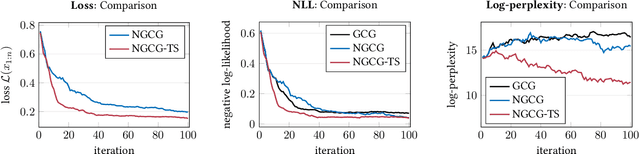

Eliciting harmful behavior from large language models (LLMs) is an important task to ensure the proper alignment and safety of the models. Often when training LLMs, ethical guidelines are followed yet alignment failures may still be uncovered through red teaming adversarial attacks. This work frames the red-teaming problem as a Markov decision process (MDP) and uses Monte Carlo tree search to find harmful behaviors of black-box, closed-source LLMs. We optimize token-level prompt suffixes towards targeted harmful behaviors on white-box LLMs and include a naturalistic loss term, log-perplexity, to generate more natural language attacks for better interpretability. The proposed algorithm, Kov, trains on white-box LLMs to optimize the adversarial attacks and periodically evaluates responses from the black-box LLM to guide the search towards more harmful black-box behaviors. In our preliminary study, results indicate that we can jailbreak black-box models, such as GPT-3.5, in only 10 queries, yet fail on GPT-4$-$which may indicate that newer models are more robust to token-level attacks. All work to reproduce these results is open sourced (https://github.com/sisl/Kov.jl).