 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoSpeech: Open-Source Toolkit for End-to-End Korean Speech Recognition
Paper and Code
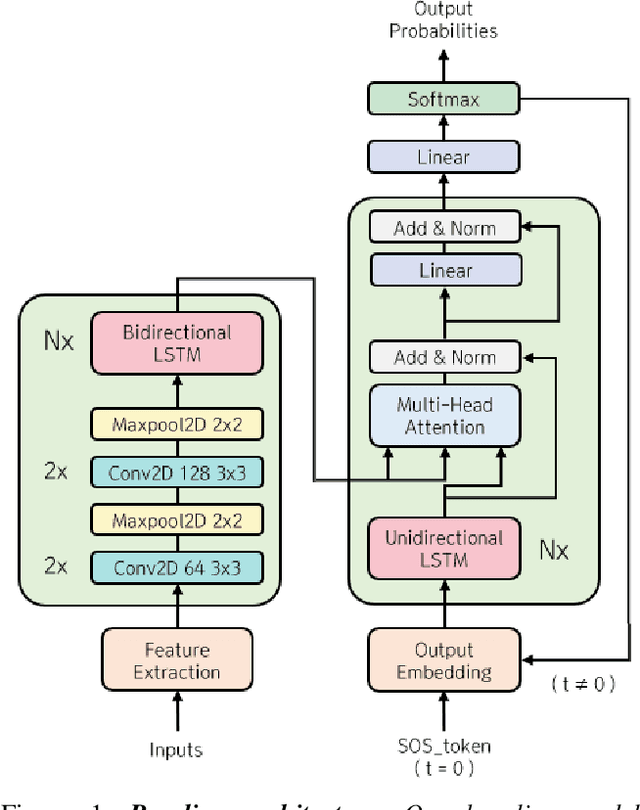

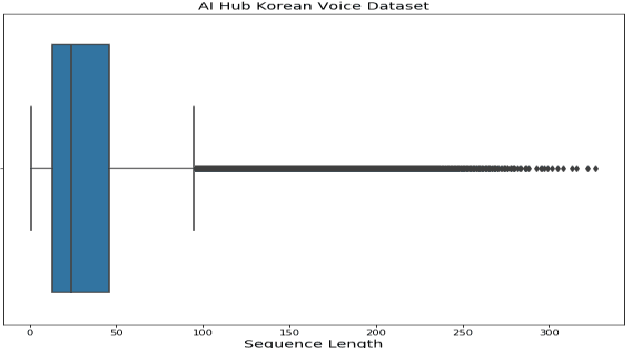

We present KoSpeech, an open-source software, which is modular and extensible end-to-end Korean automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch. Several automatic speech recognition open-source toolkits have been released, but all of them deal with non-Korean languages, such as English (e.g. ESPnet, Espresso). Although AI Hub opened 1,000 hours of Korean speech corpus known as KsponSpeech, there is no established preprocessing method and baseline model to compare model performances. Therefore, we propose preprocessing methods for KsponSpeech corpus and a baseline model for benchmarks. Our baseline model is based on Listen, Attend and Spell (LAS) architecture and ables to customize various training hyperparameters conveniently. By KoSpeech, we hope this could be a guideline for those who research Korean speech recognition. Our baseline model achieved 10.31% character error rate (CER) at KsponSpeech corpus only with the acoustic model. Our source code is available here.