 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer from Large-scale Pretrained Language Models to End-to-end Speech Recognizers
Paper and Code
Feb 16, 2022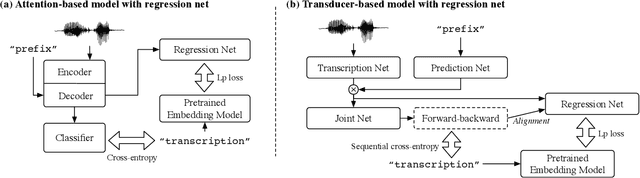
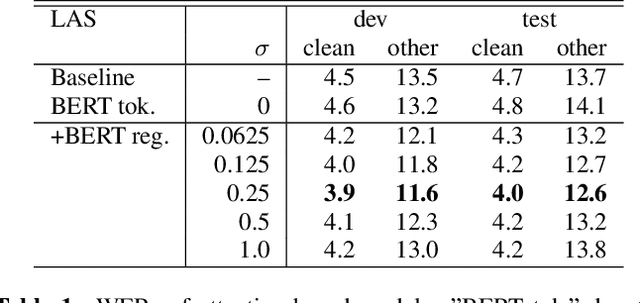
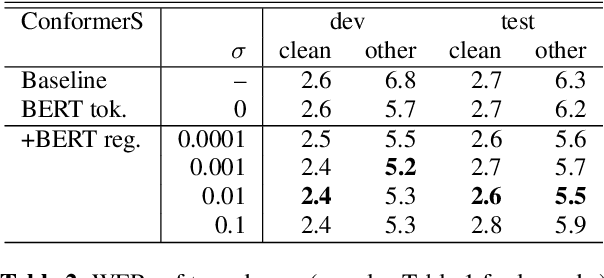
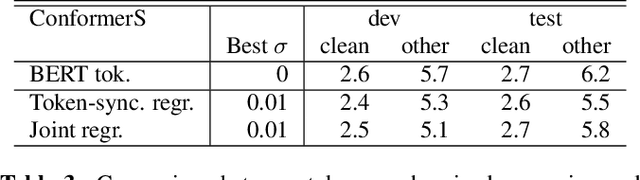
End-to-end speech recognition is a promising technology for enabling compact automatic speech recognition (ASR) systems since it can unify the acoustic and language model into a single neural network. However, as a drawback, training of end-to-end speech recognizers always requires transcribed utterances. Since end-to-end models are also known to be severely data hungry, this constraint is crucial especially because obtaining transcribed utterances is costly and can possibly be impractical or impossible. This paper proposes a method for alleviating this issue by transferring knowledge from a language model neural network that can be pretrained with text-only data. Specifically, this paper attempts to transfer semantic knowledge acquired in embedding vectors of large-scale language models. Since embedding vectors can be assumed as implicit representations of linguistic information such as part-of-speech, intent, and so on, those are also expected to be useful modeling cues for ASR decoders. This paper extends two types of ASR decoders, attention-based decoders and neural transducers, by modifying training loss functions to include embedding prediction terms. The proposed systems were shown to be effective for error rate reduction without incurring extra computational costs in the decoding phase.