 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Generation for Zero-shot Knowledge-based VQA
Paper and Code
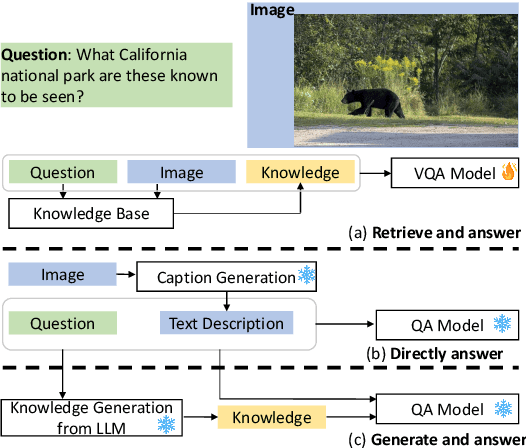



Previous solutions to knowledge-based visual question answering~(K-VQA) retrieve knowledge from external knowledge bases and use supervised learning to train the K-VQA model. Recently pre-trained LLMs have been used as both a knowledge source and a zero-shot QA model for K-VQA and demonstrated promising results. However, these recent methods do not explicitly show the knowledge needed to answer the questions and thus lack interpretability. Inspired by recent work on knowledge generation from LLMs for text-based QA, in this work we propose and test a similar knowledge-generation-based K-VQA method, which first generates knowledge from an LLM and then incorporates the generated knowledge for K-VQA in a zero-shot manner. We evaluate our method on two K-VQA benchmarks and found that our method performs better than previous zero-shot K-VQA methods and our generated knowledge is generally relevant and helpful.