 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing What to Listen to: Early Attention for Deep Speech Representation Learning
Paper and Code
Sep 03, 2020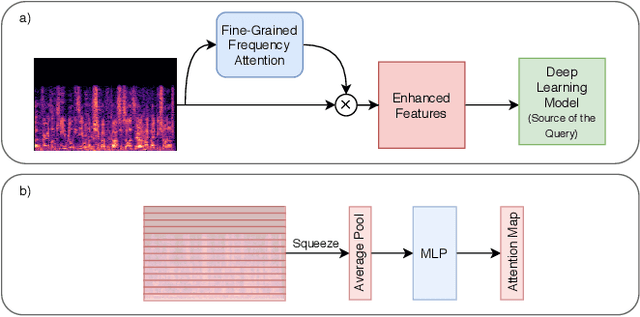
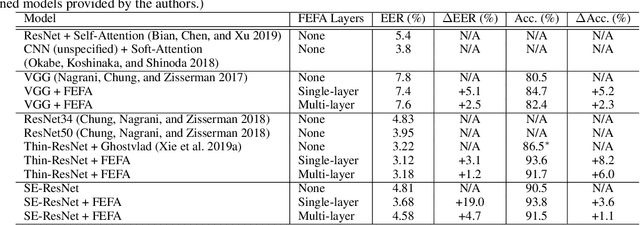
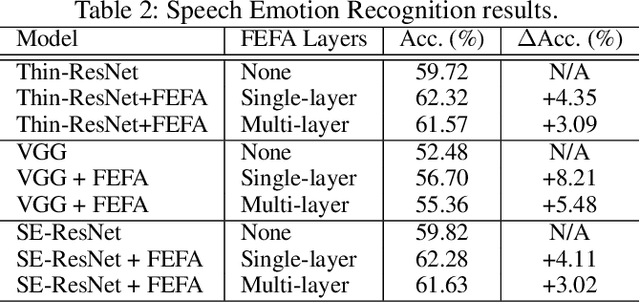
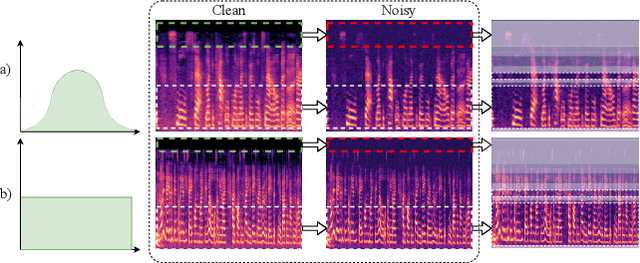
Deep learning techniques have considerably improved speech processing in recent years. Speech representations extracted by deep learning models are being used in a wide range of tasks such as speech recognition, speaker recognition, and speech emotion recognition. Attention models play an important role in improving deep learning models. However current attention mechanisms are unable to attend to fine-grained information items. In this paper we propose the novel Fine-grained Early Frequency Attention (FEFA) for speech signals. This model is capable of focusing on information items as small as frequency bins. We evaluate the proposed model on two popular tasks of speaker recognition and speech emotion recognition. Two widely used public datasets, VoxCeleb and IEMOCAP, are used for our experiments. The model is implemented on top of several prominent deep models as backbone networks to evaluate its impact on performance compared to the original networks and other related work. Our experiments show that by adding FEFA to different CNN architectures, performance is consistently improved by substantial margins, even setting a new state-of-the-art for the speaker recognition task. We also tested our model against different levels of added noise showing improvements in robustness and less sensitivity compared to the backbone networks.