 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Orthogonality does not necessarily imply a Decrease in Feature Map Redundancy in CNNs: Convolutional Similarity Minimization
Paper and Code
Nov 05, 2024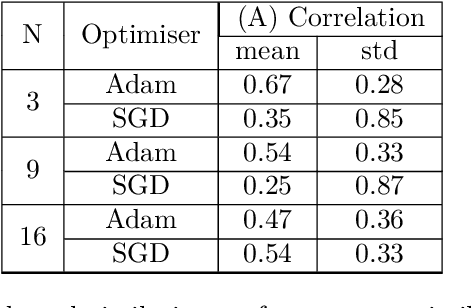



Convolutional Neural Networks (CNNs) have been heavily used in Deep Learning due to their success in various tasks. Nonetheless, it has been observed that CNNs suffer from redundancy in feature maps, leading to inefficient capacity utilization. Efforts to mitigate and solve this problem led to the emergence of multiple methods, amongst which is kernel orthogonality through variant means. In this work, we challenge the common belief that kernel orthogonality leads to a decrease in feature map redundancy, which is, supposedly, the ultimate objective behind kernel orthogonality. We prove, theoretically and empirically, that kernel orthogonality has an unpredictable effect on feature map similarity and does not necessarily decrease it. Based on our theoretical result, we propose an effective method to reduce feature map similarity independently of the input of the CNN. This is done by minimizing a novel loss function we call Convolutional Similarity. Empirical results show that minimizing the Convolutional Similarity increases the performance of classification models and can accelerate their convergence. Furthermore, using our proposed method pushes towards a more efficient use of the capacity of models, allowing the use of significantly smaller models to achieve the same levels of performance.