 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Add Functions: A Neural-Symbolic Language Model
Paper and Code
Dec 11, 2019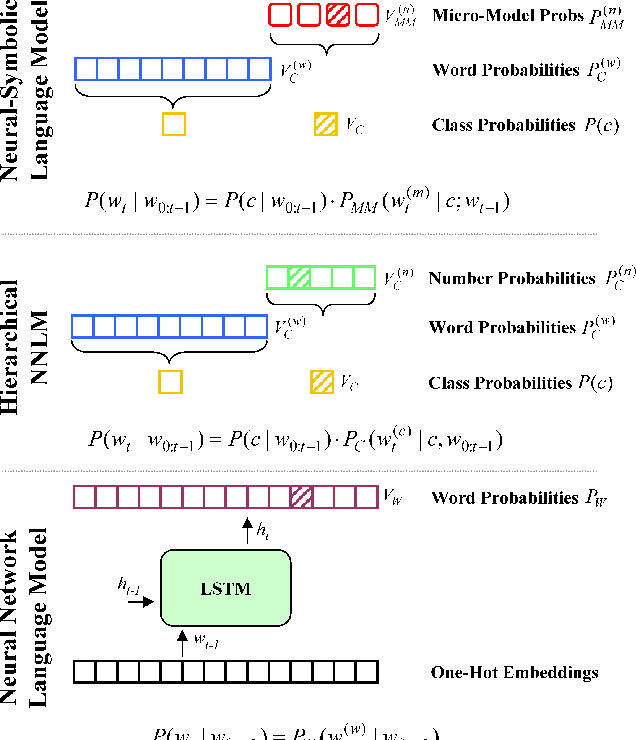

Neural network language models (NNLMs) have achieved ever-improving accuracy due to more sophisticated architectures and increasing amounts of training data. However, the inductive bias of these models (formed by the distributional hypothesis of language), while ideally suited to modeling most running text, results in key limitations for today's models. In particular, the models often struggle to learn certain spatial, temporal, or quantitative relationships, which are commonplace in text and are second-nature for human readers. Yet, in many cases, these relationships can be encoded with simple mathematical or logical expressions. How can we augment today's neural models with such encodings? In this paper, we propose a general methodology to enhance the inductive bias of NNLMs by incorporating simple functions into a neural architecture to form a hierarchical neural-symbolic language model (NSLM). These functions explicitly encode symbolic deterministic relationships to form probability distributions over words. We explore the effectiveness of this approach on numbers and geographic locations, and show that NSLMs significantly reduce perplexity in small-corpus language modeling, and that the performance improvement persists for rare tokens even on much larger corpora. The approach is simple and general, and we discuss how it can be applied to other word classes beyond numbers and geography.