 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Multi-Objective Reinforcement Learning with Policy Gradient Based Algorithm
Paper and Code
May 28, 2021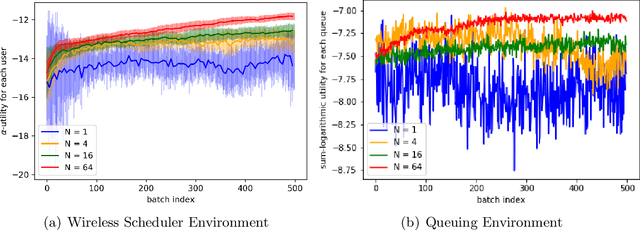


Many engineering problems have multiple objectives, and the overall aim is to optimize a non-linear function of these objectives. In this paper, we formulate the problem of maximizing a non-linear concave function of multiple long-term objectives. A policy-gradient based model-free algorithm is proposed for the problem. To compute an estimate of the gradient, a biased estimator is proposed. The proposed algorithm is shown to achieve convergence to within an $\epsilon$ of the global optima after sampling $\mathcal{O}(\frac{M^4\sigma^2}{(1-\gamma)^8\epsilon^4})$ trajectories where $\gamma$ is the discount factor and $M$ is the number of the agents, thus achieving the same dependence on $\epsilon$ as the policy gradient algorithm for the standard reinforcement learning.