 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint NMF for Identification of Shared Features in Datasets and a Dataset Distance Measure
Paper and Code
Jul 11, 2022
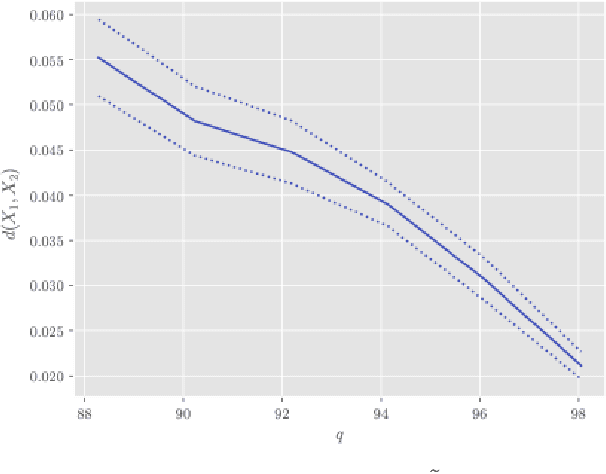
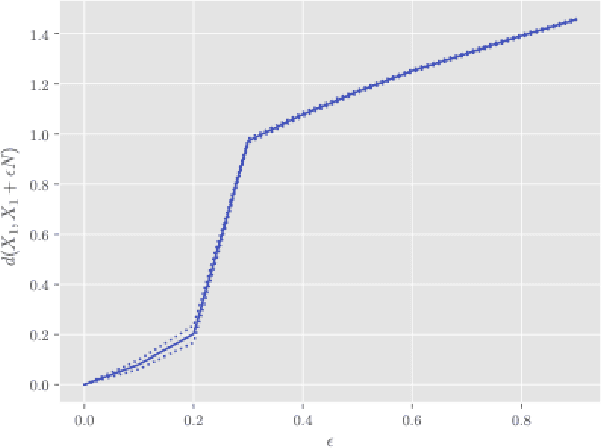
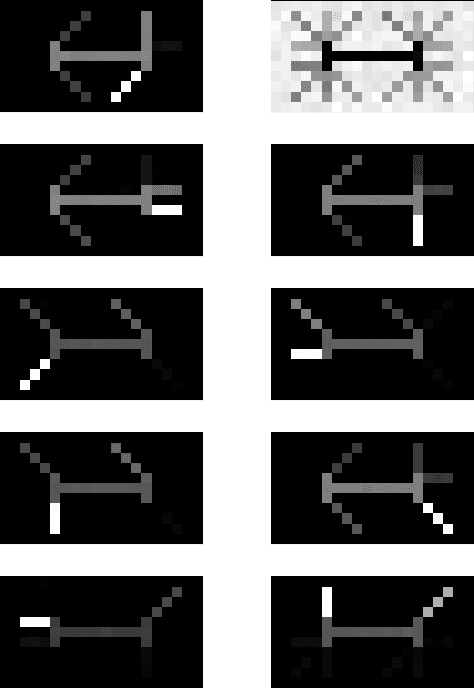
In this paper, we derive a new method for determining shared features of datasets by employing joint non-negative matrix factorization and analyzing the resulting factorizations. Our approach uses the joint factorization of two dataset matrices $X_1,X_2$ into non-negative matrices $X_1 = AS_1, X_2 = AS_2$ to derive a similarity measure that determines how well a shared basis for $X_1, X_2$ approximates each dataset. We also propose a dataset distance measure built upon this method and the learned factorization. Our method is able to successfully identity differences in structure in both image and text datasets. Potential applications include classification, detecting plagiarism or other manipulation, and learning relationships between data sets.