 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Global and Local Hierarchical Priors for Learned Image Compression
Paper and Code
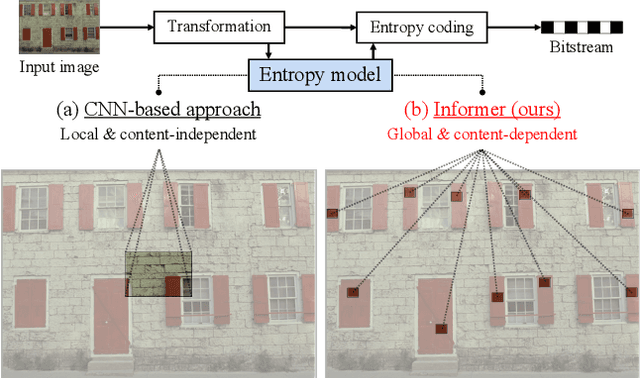


Recently, learned image compression methods have shown superior performance compared to the traditional hand-crafted image codecs including BPG. One of the fundamental research directions in learned image compression is to develop entropy models that accurately estimate the probability distribution of the quantized latent representation. Like other vision tasks, most of the recent learned entropy models are based on convolutional neural networks (CNNs). However, CNNs have a limitation in modeling dependencies between distant regions due to their nature of local connectivity, which can be a significant bottleneck in image compression where reducing spatial redundancy is a key point. To address this issue, we propose a novel entropy model called Information Transformer (Informer) that exploits both local and global information in a content-dependent manner using an attention mechanism. Our experiments demonstrate that Informer improves rate-distortion performance over the state-of-the-art methods on the Kodak and Tecnick datasets without the quadratic computational complexity problem.