 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Deep Learning for Car Detection
Paper and Code
Jul 14, 2016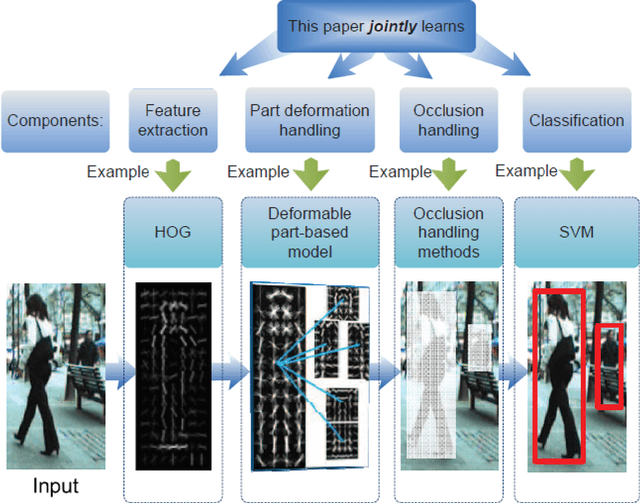
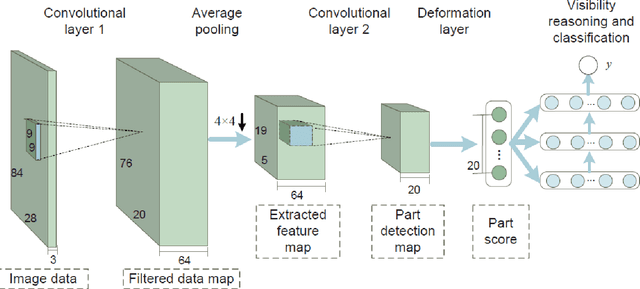
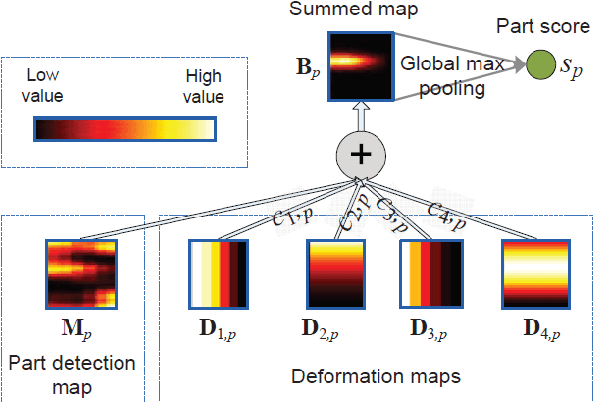
Traditional object recognition approaches apply feature extraction, part deformation handling, occlusion handling and classification sequentially while they are independent from each other. Ouyang and Wang proposed a model for jointly learning of all of the mentioned processes using one deep neural network. We utilized, and manipulated their toolbox in order to apply it in car detection scenarios where it had not been tested. Creating a single deep architecture from these components, improves the interaction between them and can enhance the performance of the whole system. We believe that the approach can be used as a general purpose object detection toolbox. We tested the algorithm on UIUC car dataset, and achieved an outstanding result. The accuracy of our method was 97 % while the previously reported results showed an accuracy of up to 91 %. We strongly believe that having an experiment on a larger dataset can show the advantage of using deep models over shallow ones.