 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterNorm: Fast Iterative Normalization
Paper and Code
Dec 06, 2024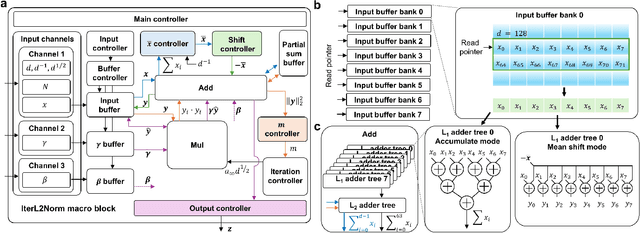

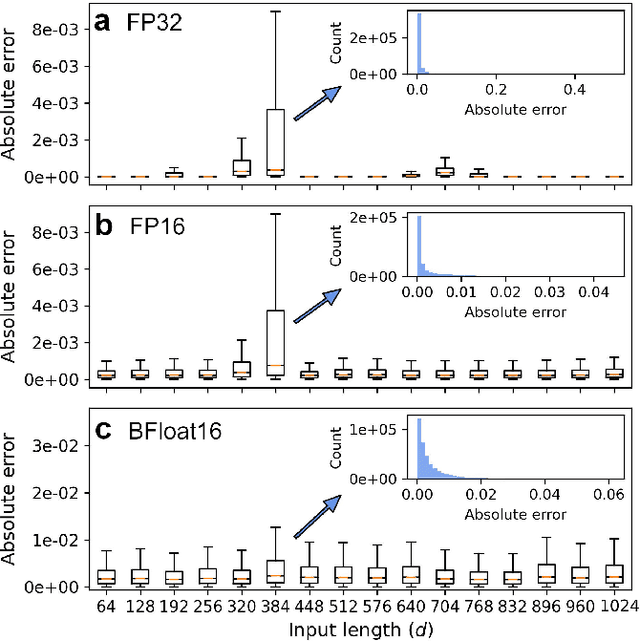

Transformer-based large language models are a memory-bound model whose operation is based on a large amount of data that are marginally reused. Thus, the data movement between a host and accelerator likely dictates the total wall-clock time. Layer normalization is one of the key workloads in the transformer model, following each of multi-head attention and feed-forward network blocks. To reduce data movement, layer normalization needs to be performed on the same chip as the matrix-matrix multiplication engine. To this end, we introduce an iterative L2-normalization method for 1D input (IterNorm), ensuring fast convergence to the steady-state solution within five iteration steps and high precision, outperforming the fast inverse square root algorithm in six out of nine cases for FP32 and five out of nine for BFloat16 across the embedding lengths used in the OPT models. Implemented in 32/28nm CMOS, the IterNorm macro normalizes $d$-dimensional vectors, where $64 \leq d \leq 1024$, with a latency of 112-227 cycles at 100MHz/1.05V.