 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Rule Extension for Logic Analysis of Data: an MILP-based heuristic to derive interpretable binary classification from large datasets
Paper and Code
Oct 25, 2021
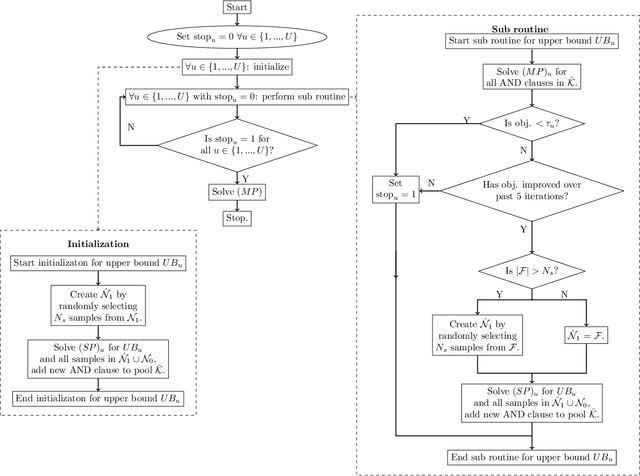
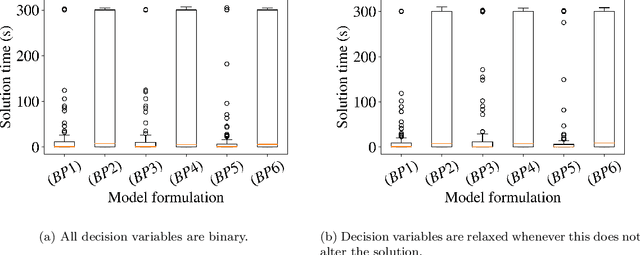
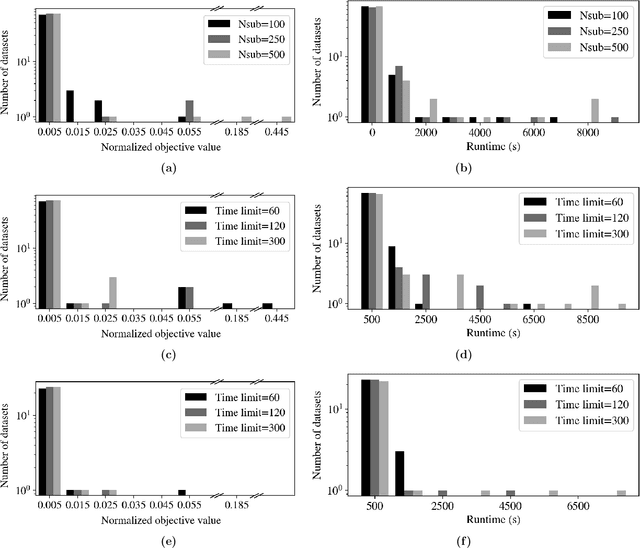
Data-driven decision making is rapidly gaining popularity, fueled by the ever-increasing amounts of available data and encouraged by the development of models that can identify beyond linear input-output relationships. Simultaneously the need for interpretable prediction- and classification methods is increasing, as this improves both our trust in these models and the amount of information we can abstract from data. An important aspect of this interpretability is to obtain insight in the sensitivity-specificity trade-off constituted by multiple plausible input-output relationships. These are often shown in a receiver operating characteristic (ROC) curve. These developments combined lead to the need for a method that can abstract complex yet interpretable input-output relationships from large data, i.e. data containing large numbers of samples and sample features. Boolean phrases in disjunctive normal form (DNF) are highly suitable for explaining non-linear input-output relationships in a comprehensible way. Mixed integer linear programming (MILP) can be used to abstract these Boolean phrases from binary data, though its computational complexity prohibits the analysis of large datasets. This work presents IRELAND, an algorithm that allows for abstracting Boolean phrases in DNF from data with up to 10,000 samples and sample characteristics. The results show that for large datasets IRELAND outperforms the current state-of-the-art and can find solutions for datasets where current models run out of memory or need excessive runtimes. Additionally, by construction IRELAND allows for an efficient computation of the sensitivity-specificity trade-off curve, allowing for further understanding of the underlying input-output relationship.